在上一篇文章中介绍了基本的网络服务器模型,但是一次只为一个客户端提供服务是不现实的。更好的方法是创建一个并发服务器,为每一个客户端创建一个单独的逻辑流。
构造并发程序有如下几种方法:
- 多进程并发编程
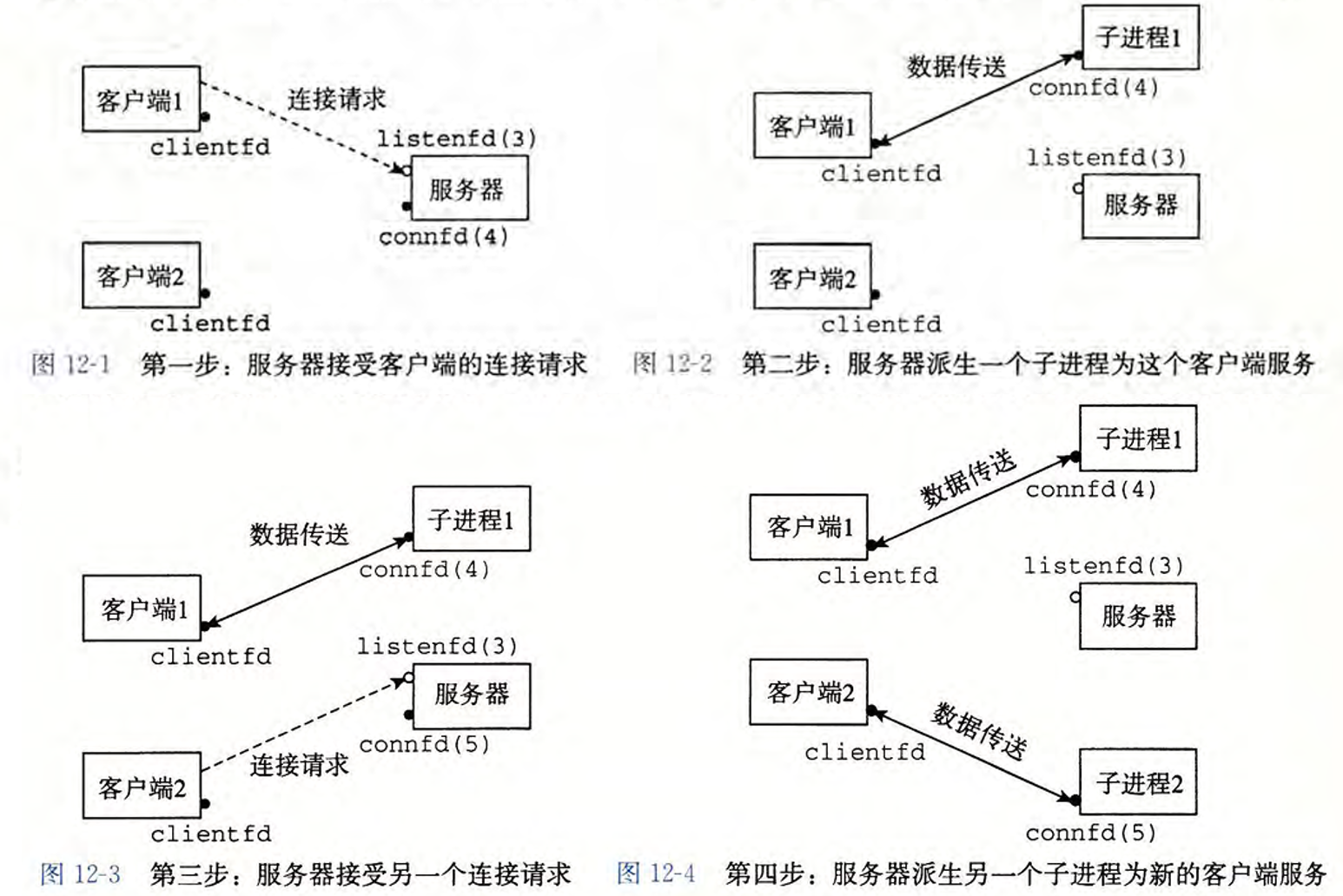
在父进程中接受客户端连接请求,然后创建一个新的子进程来为每个新客户端提供服务。缺点是每个进程有独立的地址空间,使得进程共享状态信息变得困难,为了共享必须使用显示的IPC(进程间通信)机制,而开销是很高的。
- I/O多路复用并发编程
多路指的是多个socket网络连接,复用指的是复用一个线程、使用一个线程来检查多个文件描述符(Socket)的就绪状态。多路复用主要有三种技术:select,poll,epoll。epoll是最新的,也是目前最好的多路复用技术。
I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
相比于多进程,IO多路复用是在单一进程上下文中,状态得以共享;缺点就算编码复杂。尽管如此,现代高性能服务器(例如 Node.js、 nginx 和 Tornado)使用的都是基于 I/O 多路复用的事件驱动的编程方式,主要是因为相比于进程和 线程的方式,它有明显的性能优势。
- 多线程并发编程
多线程的执行模型在某些方面和多进程的执行模型是相似的。每个进程开始生命周期时都是单一线程,这个线程称为主线程(main thread)。在某一时刻,主线程创建一个对等线程(peer thread) , 从这个时间点开始,两个线程就并发地运行。最后,因为主线程执行一个慢速系统调用,例如 read 或者sleep, 或者因为被系统的间隔计时器中断,控制就会通过上下文切换传递到对等线程。执行一段时间后再传递回主线程。
Posix线程是C程序中处理线程的标准接口,相关函数包括pthread_create、pthread_detach等等。
本项目中采用了 epoll I/O多路复用 + 线程池 + 模拟Proactor 的并发模型来实现一个高并发服务器。本文将介绍线程池和模拟Proactor的具体作用和实现。
线程池解决了什么问题 #
在多线程并发模型中,如果每来一个请求就 pthread_create 一次、处理完 pthread_join 销毁,那么每个线程的创建涉及分配栈空间(约 8MB)、初始化内核 task_struct、建立 TLS(线程局部存储)——这些开销积累起来,CPU 时间全耗在线程管理而非业务处理上。
线程池的思路很简单:预创建 N 个常驻线程,复用它们。 新任务来了放进任务队列,哪个线程空闲就抢走处理。关键模型是生产者-消费者:
生产者(主线程) 消费者(工作线程)
│ │
├─ append(task) ──→ 任务队列 ←── run() 循环取任务
│ (加锁) │
└── 立刻返回 └── request->process()具体的,主线程为异步线程,负责监听文件描述符,接收socket新连接,若当前监听的socket发生了读写事件,然后将任务插入到请求队列,扔完任务立刻回去继续 epoll_wait,不等任何工作线程。8 个工作线程在 run() 里无限循环:拿锁 → 检查队列 → 有任务就取、没任务就 wait 睡觉。
生产者-消费者模型天然消峰——工作线程忙不过来时,任务在队列里排队(最多堆积 m_max_requests = 10000 个),不会丢。队满了 append 返回 false,主线程自行决策是否放弃当前连接。
线程池的实现要点 #
项目中线程池是模板类 threadpool<T>,所有代码在单头文件 include/threadpool.h 中(模板类不能分离到 .cpp)。
数据结构:
| 成员 | 类型 | 作用 |
|---|---|---|
m_workqueue |
std::list<T*> |
任务队列,线性链表 |
m_mutex |
locker |
保护队列的互斥锁 |
m_cond |
cond |
条件变量,通知"有任务了" |
m_threads |
pthread_t* |
线程 ID 数组 |
m_stop |
bool |
关闭标志 |
构造线程池
template <typename T>
threadpool<T>::threadpool(int thread_num, int max_requests)
{
// 构造函数
// 1. 合法
if (thread_num <= 0) thread_num = 1;
if (max_requests <= 0) max_requests = 1;
// 2. 赋值
m_thread_num = thread_num;
m_max_requests = max_requests;
m_threads = new pthread_t[thread_num];
m_stop = false;
// 3. 创建thread_num个线程
for (int i = 0; i < thread_num; i++) {
pthread_create(&m_threads[i], nullptr, worker, this);
pthread_detach(m_threads[i]);
}
}根据 thread_num 参数(默认 8)循环 pthread_create,每个线程入口是静态函数 worker,通过第四个参数 this 把线程池对象自己传进去。创建后 pthread_detach 分离——线程结束后自行回收资源,不需要主线程去 join。
run() - 工作线程的核心循环
template <typename T>
void threadpool<T>::run()
{
// 现在线程要启动了,一个循环
while (true)
{
// 1. 获取锁
m_mutex.lock();
// 2. 如果队列为空 且 没有停止 就等
while (m_workqueue.empty() && !m_stop) {
// 这个wait会自动放弃锁,然后线程等待,直到在append函数中signal_one了才唤醒
// 重新获取锁,继续处理
m_cond.wait(m_mutex.get());
}
if (m_stop) {
m_mutex.unlock();
break;
}
// 3. 从队列中取出一个任务
T* request = m_workqueue.front();
m_workqueue.pop_front();
// 4. 保证**取出任务**的原子性
m_mutex.unlock();
// 执行HTTP请求
request->process();
}
}append() - 生产者
template <typename T>
bool threadpool<T>::append(T* request)
{
// 1. 获取锁
m_mutex.lock();
// 2. 如果队列慢了就解锁,返回false
if ((int)m_workqueue.size() >= m_max_requests) {
m_mutex.unlock();
return false;
}
// 3. 加入
m_workqueue.push_back(request);
// 4. 唤醒一个在run中wait的睡眠线程
m_cond.signal_one();
// 5. 解锁,返回
m_mutex.unlock();
return true;
}worker() - 线程处理函数
内部访问私有成员函数run,完成线程处理要求。
template <typename T>
void* threadpool<T>::worker(void* arg)
{
// 线程的工作函数
// 首先arg是传入的this,进行强制类型转换,也就是把线程池对象传进来
threadpool* pool = (threadpool*)arg;
// 然后调用线程池的run函数来运行线程
pool->run();
return nullptr;
}几个关键点:
-
条件变量的
wait用while不用if:伪唤醒——内核可能无故唤醒线程,或者多个线程被唤醒后抢锁过程中另一个线程已经把唯一的任务抢走了。while让醒来者重新检查条件。 -
取任务时持锁,执行时不持锁:
request->process()可能有磁盘 I/O(读文件、写日志),耗时毫秒级。锁保护的是共享变量,尽量保持临界区的执行时间短。 -
cond.wait()传裸指针m_mutex.get():我的locker.h封装了pthread_mutex_t,.get()返回内部裸锁地址,给条件变量 wait 使用。具体的代码可以查看locker.h的源代码。
Reactor 模式 #
Reactor 模式中,主线程(I/O处理单元)只负责监听文件描述符上是否有事件发生,有的话立即通知工作线程(逻辑单元),读写数据、接受新连接及处理客户请求均在工作线程中完成。通常由同步I/O实现。
主线程返回就绪事件(事件分离)
↓
主线程遍历就绪 fd 列表(事件分发)
↓
对每个就绪 fd,调用对应的 handler:
listenfd → accept_handler (接受新连接)
connfd → read_handler (读请求)
connfd → write_handler (写响应)在 Reactor 模式下,工作线程拿到的是"裸 fd",它要自己调 recv 把数据从内核缓冲区读出来,接受新连接。读写和业务处理在同一个工作线程里完成:
主线程: 发现 fd=5 可读 → 把 fd=5 分发给工作线程 A
工作线程 A: recv(fd=5) → 读数据 → parse → 处理 → sendProactor 模式 #
Proactor 把 I/O 操作从工作线程剥离出来,交给更底层的内核机制完成。
真正 Proactor(Windows IOCP):
1. 主线程发起异步读 → 内核开始将数据从 socket 缓冲区拷到用户 buffer
2. 内核完成拷贝 → 通知主线程"I/O 完成"
3. 主线程分发 → 工作线程直接拿到已填满数据的 buffer但是 Linux 的 aio_read 对 socket 支持极差(主要为磁盘 I/O 设计),因此本项目用的是同步IO模拟Proactor。
同步I/O模拟 Proactor #
项目采用主线程"代理 I/O"的折中方案。对工作线程来说,它拿到的就是已读好的数据,效果等同于 Proactor。不同的是,I/O 不是内核异步做的,是主线程同步 recv 做的。
同步I/O的具体流程:
- 主线程在epoll内核事件表上注册socket的读就绪事件。
- 主线程调用epoll_wait等待socket上有数据可读。
- 当socket上有数据可读,epoll_wait通知主线程,主线程从socket循环读取数据,读入封装了的请求对象的缓冲区,直到没有更多数据可读。然后将封装的请求对象的指针插入请求队列。
- 睡眠在请求队列上某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往epoll内核事件表中注册该socket上的写就绪事件
- 主线程调用epoll_wait等待socket可写。
- 当socket上有数据可写,epoll_wait通知主线程。主线程往socket上写入服务器处理客户请求的结果。
这和真 Proactor 的区别只有一点:
| 真 Proactor | 本项目 | |
|---|---|---|
| I/O 谁做 | 内核异步 aio_read |
主线程同步 recv |
| 主线程阻塞吗 | 不,发起后立刻返回 | 短暂阻塞等 recv(但都是 LT 模式,数据已在缓冲区) |
| 工作线程感知 | 拿到已读好的数据 | 拿到已读好的数据 ✓ |
为什么这样设计:Linux 下真异步 I/O 对 socket 不可用,而 Reactor 模式的工作线程和主线程都要处理 I/O 细节(工作线程自带 recv 逻辑),主线程读到不完整数据时还要处理 NO_REQUEST 和 ONESHOT 重新注册(本项目做了:process() 返回 NO_REQUEST 时工作线程通过 m_epoller->mod_fd 重新注册监听)。模式职责分离更清晰。
三种模式对比 #
| Reactor | 真 Proactor | 本项目(模拟 Proactor) | |
|---|---|---|---|
| 事件分离 | epoll(主线程) | epoll(主线程) | epoll(主线程) |
| I/O 谁做 | 工作线程自己 recv |
内核异步 aio_read |
主线程同步 recv |
| 业务处理谁做 | 工作线程 | 工作线程 | 工作线程 |
| 工作线程拿到什么 | 裸 fd | 已读好的数据 | 已读好的数据 |
| 主线程阻塞 | 不阻塞(只分发) | 不阻塞 | 短暂阻塞(LT 缓冲已有数据) |
三种模式的共同点是事件分离器都在主线程。分歧点在 I/O 归属:Reactor 分给工作线程,Proactor 交给内核,本项目由主线程代理——把 I/O 和业务处理在逻辑上分离,同时规避了 Linux AIO 的限制。