一、进程模型 #
1. 进程的定义与概念 #
从资源管理的角度来看:进程是对CPU的抽象,地址空间是对内存的抽象,文件系统是对磁盘的抽象。
进程是具有独立功能的程序关于某个数据集合上的一次运行活动,是系统进行资源分配和调度的独立单位。
进程是程序的一次执行过程,是正在运行程序的抽象。每一个进程有自己独立的地址空间。操作系统将单个(或有限个)物理 CPU 虚拟化为多个“虚拟 CPU”,让每个进程认为自己独占了一个 CPU。操作系统通过进程来分配CPU,通过进程来管理CPU。
进程是动态的而程序的静态的,进程有生命周期;一个程序可以对应多个进程。
2. 进程模型的组成 #
- 进程的状态
三种基本状态:运行态、就绪态、等待态
此外还有其他状态如创建(已完成创建所必要的工作如PID但是未同意执行该进程)、终止(完成数据统计工作、资源回收)、挂起(把进程从内存转到磁盘,腾出内存空间。等待态就是阻塞,仍在内存中,不占用CPU但是还在占用内存)。
- 进程的数据结构
进程控制块PCB(Process Control Block),又称进程属性,记录属性,描述进程的动态变化过程。例如在Linux中是task_struct。
操作系统通过PCB来控制和管理进程,进程与PCB是一一对应的,PCB是系统感知进程存在的唯一标志。那么进程表就是所有进程的PCB的集合。
PCB的主要信息:
- 进程描述信息:唯一进程标识符PID;进程名(通常基于可执行文件名);用户标识符UID;等等
- 进程控制信息:进程状态;优先级priority;可执行文件名;调度信息;进程的队列指针;进程的消息队列指针;等等
- 所拥有的资源和使用情况:虚拟地址空间现状;打开文件列表;等等
- CPU现场信息:寄存器值(通用、PC、PSW、栈指针等);指向该进程的页表指针;等等
与进程执行的相关信息就在PCB中寻找,比如在系统调用返回时,需要重新调度其他进程运行,原来被打断的进程的信息不可能一直保持在系统栈中,而是会先保存在其PCB中;而后重新运行时再从PCB中取出进程相关信息。再比如Linux中在task_struct中的mm_struct会包含页表的指针,这样在进程切换的时候调度器可以将新进程的页表地址加载在CPU中。
- 进程的地址空间
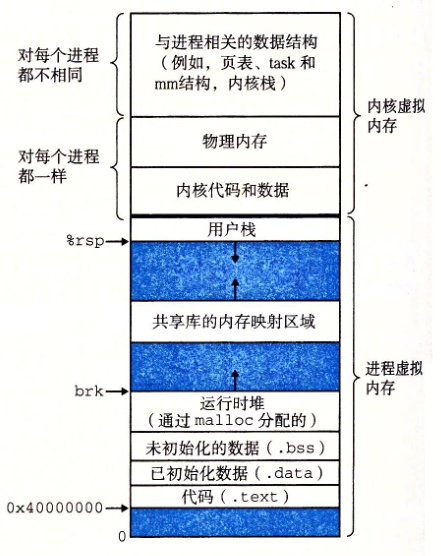
操作系统给每个进程分配了一个地址空间,其布局如上图。“地址空间”是一个逻辑概念,定义了进程理论上可以访问的所有虚拟地址的范围;页表是一个物理数据结构,记录了地址空间中哪些区域已经被映射到物理内存。CPU在取指或者访问数据时,给出的是一个虚拟地址,并利用这个虚拟地址去查页表,从而去找到对应的物理内存。可以说,地址空间是对物理内存的抽象,是给CPU提供便利的。而具体的寻址还是需要页表和物理内存来实现。同时这样的抽象也为地址的合理性检查提供了便利。
可以发现每个进程的地址空间分为两个部分:
- 高地址处是内核空间,一部分是与进程相关的私有数据,如内核栈、进程控制块PCB、页表等等,这些在每个进程中是独立的,每个进程都不相同;另一部分则是内核代码和数据,这些则是每个进程共享的,具体的方式是每个进程的页表负责映射“高地址内核空间”的那些页表项,都指向物理内存中完全相同的那一页,对每个进程都一样。比如PCB就在这里。
- 低地址处是用户空间,包括
.rodata,.bss,.data,.text段以及堆栈等等。
可以使用
cat /proc/[PID]/maps来查看
在Linux中,struct mm_struct *mm是整个进程用户态虚拟地址空间的总入口,包含页目录、虚拟内存区域链表等全部信息。如pgd_t *pgd是页目录的起始地址,在x86中会在利用这个值时保存在CR3寄存器中。
- 进程队列(表)
操作系统为每一类进程建立一个或多个队列,队列元素为PCB,伴随进程状态的改变,PCB可能会从一个队列进入另一个队列。
- 进程状态转换和进程控制
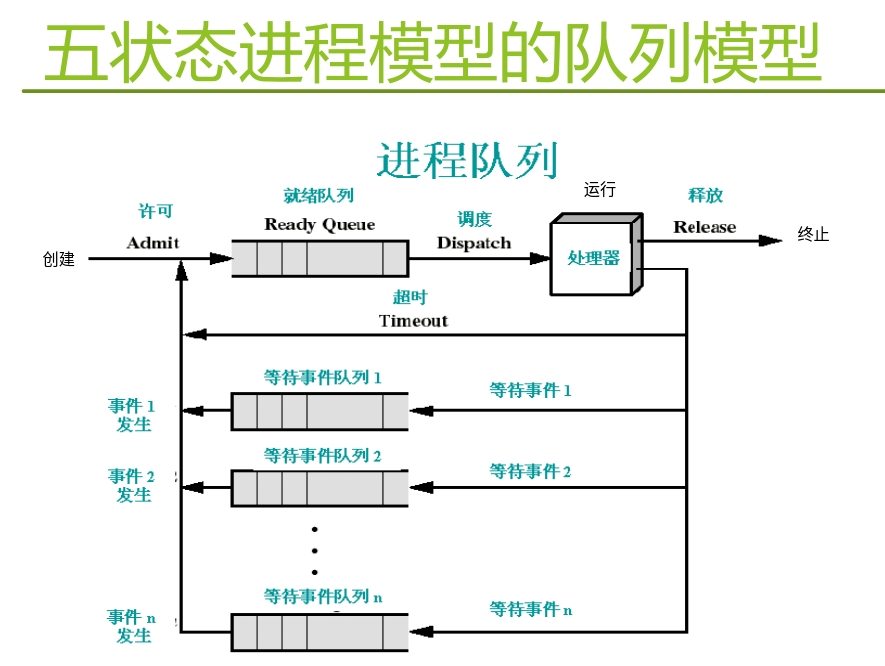
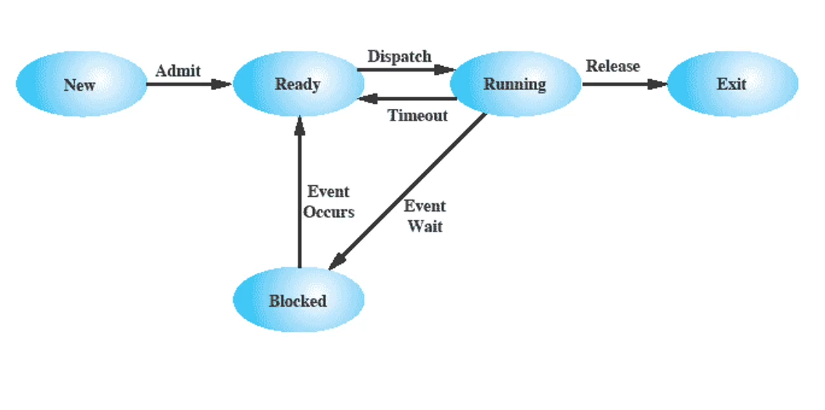
进程状态转换需要有控制操作,这些操作由具有特定功能的原语完成(原子操作,执行不可被中断,更准确地说是在执行的时候disable interrupt,不响应中断)。如创建、撤销、阻塞、挂起等等。
进程何时创建?在系统初始化/由现有进程派生新进程/提交一个程序执行等等。
创建时分配一个pid和PCB并分配地址空间。在unix中创建是通过fork()和exec()来完成的。在UNIX中fork()会以一次一页的方式复制父进程的地址空间,在Linux中利用存储管理模块中的copy-on-write(COW)的技术进行优化(注:这个技术不是来自于fork而是来自于存储管理模块)。
二、线程模型 #
为何需要引入线程?应用的需要、开销(轻量进程)、性能。
应用:在web服务器中如何提高效率?使用多线程。在没有线程的时候可以使用一个服务进程顺序编程、采用非阻塞I/O的有限状态机(涉及到系统调用select() poll() epoll())
线程是进程中的一个运行实体,进程是资源的拥有者和调度单位,线程是CPU的调度单位。每个线程都有自己独立的栈,但是都是在一个进程的地址空间中的。
线程具体是如何实现的呢?有三种:
- 用户级线程:在用户空间建立线程库,内核只能感知到进程的存在,进程通过
Run-time system来管理线程;线程的切换不需要内核态特权。e.g. POSIX Pthreads。但是有一个问题就是线程的系统调用仍然需要以进程的身份进入内核,若是阻塞的调用会导致整个进程阻塞。解决办法是要么修改系统调用为非阻塞的(可能由runtime system来细节实现),要么重新实现对应系统调用的io函数。 - 内核级线程:内核管理所有线程,并向应用程序提供接口,以线程为基础进行调度,线程的切换需要内核支持。e.g. Windows。
- 混合模型:用户态线程和内核线程一一对应,在用户态创建,在内核态调度。e.g. Solaris。
三、协程coroutine #
是用户态的(没有进内核的开销)、可主动挂起和恢复的执行单元,调度由程序员控制而不是操作系统内核。
协程运行在线程之上,当一个协程执行完成后,可以选择主动让出,让另一个协程运行在当前线程之上。协程并没有增加线程数量,只是在线程的基础之上通过分时复用的方式运行多个协程,而且协程的切换在用户态完成,切换的代价比线程从用户态到内核态的代价小很多。所以协程适用于IO密集型的任务。
参考:https://zhuanlan.zhihu.com/p/172471249