一、文件系统基本概念 #
1.1 文件是什么? #
文件是对磁盘的抽象。文件是一组带标识(标识即为文件名)的、在逻辑上有完整意义的信息项序列。其中信息项:构成文件内容的基本单位(单个字节,或多个字节),各信息项之间具有顺序关系。
信息项0 │ 信息项1 │ …… │ 信息项i │ …… │ 信息项n-1 │
↑ 读写指针文件内容的意义由文件的建立者和使用者解释。
1.2 文件分类(UNIX) #
| 类型 | 说明 |
|---|---|
| 普通文件(regular) | 用户信息,ASCII 或二进制 |
| 目录文件(directory) | 管理文件系统的系统文件 |
| 特殊文件(special) | 字符设备文件(串行 I/O)、块设备文件(磁盘) |
| 管道文件、套接字、符号链接文件 | 进程间通信等 |
1.3 文件系统 #
统一管理信息资源,管理文件的存储、检索、更新,提供安全可靠的共享和保护手段。
核心功能:
- 统一管理磁盘空间,实施分配与回收
- 实现文件的按名存取(名字空间 ↔ 磁盘空间的映射)
- 实现文件信息共享,提供可靠性和安全保障
- 向用户提供方便使用的接口
- 提供与 I/O 系统的统一接口
1.4 典型文件系统 #
- 本地文件系统:EXT4、XFS、Btrfs、NTFS、APFS、OpenZFS、exFAT
- 移动设备专用文件系统:F2FS
- 分布式文件系统:HDFS、CephFS、GlusterFS、Lustre
二、文件的逻辑结构与存取方式 #
2.1 逻辑结构 #
从用户角度看文件,由用户的访问方式确定:
| 类型 | 特点 | 适用场景 |
|---|---|---|
| 流式文件 | 字节序列,无结构 | 源程序、可执行文件 |
| 记录式文件 | 由记录序列组成,每个记录内部有结构 | 数据库、信息管理系统 |
除了看成字节序列、记录序列外还有树、堆、索引等等方式。
2.2 存取方式 #
- 顺序存取:按字节/记录依次读取,自动移动读写指针
- 随机存取:从任意位置读写(如 UNIX 的
seek操作)
三、存储介质与物理块 #
3.1 相关术语 #
| 术语 | 含义 |
|---|---|
| 扇区(Sector) | 磁盘的物理存储单元,通常 512B,一般保证扇区写入的原子性 |
| 物理块 / 磁盘块 / 数据块 / 块 / 簇 | 信息存储、传输、分配的基本单位,由若干扇区组成 |
| 分区(Partition) | 把一个物理磁盘的存储空间划分为几个相互 |
| 独立的部分,每个分区是独立的文件系统 | |
| 卷(Volume) | 逻辑分区,一个文件卷上包含文件系统信息、文件、未分配空间 |
| 格式化(Format) | 在卷上建立文件系统的过程 |
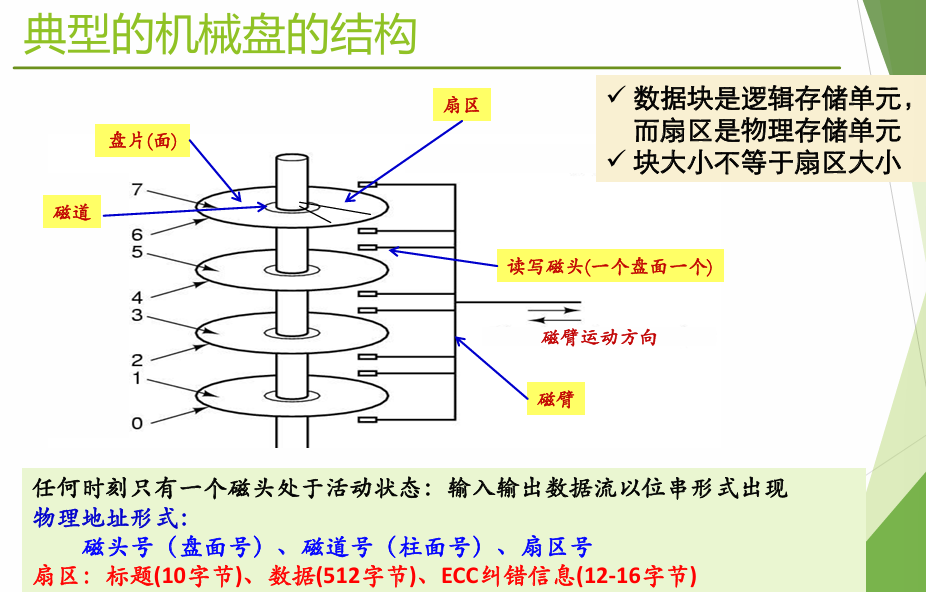
在有了块/簇之后,扇区差不多就被屏蔽了,至于一个块可以有多少个扇区可以自己定义。块的索引用逻辑块号LBA来进行。对于OS来说看不到真正的PBA,所谓的数据块一开始也都是LBA,都需要经过映射才能得到真正的物理地址来读取真正的数据。
在硬件层面,磁盘读写的最小单位是扇区,但是对于操作系统来说,文件系统将多个连续的扇区组成一个逻辑块,每次IO操作至少读写一个完整的块。块是存储分配的最小单位。
3.2 机械硬盘HDD #
一次访盘请求 = 读/写 + 磁盘地址(磁头号、柱面号、扇区号) + 内存地址。
三个动作:
- 寻道:磁臂带动着磁头移到指定磁道,往往需要较长时间
- 旋转延迟:等待指定扇区旋转到磁头下
- 数据传输:数据在磁盘与内存之间的实际传输
3.3 固态驱动器SSD #
电子过程(组件关系):
OS(LBA) ←→ SSD 控制器 ←→ DRAM 缓存(含 FTL 映射表)
|
↓
NAND 闪存块(实际存储)- 读:OS 发出 LBA → 控制器查 FTL 映射表定位 NAND 物理页 → 读入 DRAM → 传回 OS
- 写:OS 发出 LBA + 数据 → 控制器先写 DRAM → FTL 更新映射 → 异步刷入 NAND
- 最小写入单位是页(
4KB~16KB),只能写空页或擦除后重写;最小擦除单位是块(通常64~256页),远大于写入单位。这里的块是SSD中的擦写概念的,与LBA无关。 - 闪存物理存储单元(块、页)离散分布,无法直接对应操作系统的连续逻辑地址。
- 块有擦除寿命限制,需要磨损均衡(Wear Leveling)延长寿命。
- FTL(Flash Translation Layer)在底层完成逻辑地址到物理地址的映射,操作系统只需使用 LBA(Logical Block Address)访问,无需关心内部细节。
对于 SSD 没有机械部件了,只需要考虑数据传输的时间。
3.4 LBA 与 PBA #
| LBA(Logical Block Address) | PBA(Physical Block Address) | |
|---|---|---|
| 定义 | 逻辑块地址,OS 眼中磁盘的"线性连续地址" | 物理块地址,NAND 闪存中实际的存储位置 |
| 发出方 | 操作系统(文件系统/块层) | SSD 控制器内部,经过 FTL 映射后得到 |
| 特性 | 连续的、线性的;OS 认为磁盘就是一串 0, 1, 2, … 号块 | 离散的、非线性的;受限于 NAND 的物理布局和状态 |
| 是否可见 | 操作系统可见 | 操作系统不可见,完全由 FTL 内部管理 |
| 映射关系 | LBA →(FTL 转换)→ PBA | PBA 可能随写时重定向而变化(同一个 LBA 可映射到不同 PBA) |
核心思想:LBA 是对 OS 的抽象承诺——“我就给你一串块号,你随便读写”,这是OS对于文件系统读写的接口;PBA 是 SSD 内部实现——受限于 NAND 不能原地覆盖、有擦除寿命等物理约束。FTL 在中间做翻译,使得 OS 可以用简单的线性块号访问,而 SSD 底层可以做写时重定向、垃圾回收、磨损均衡等优化,OS 完全不用关心。
在SSD中,由FTL来进行二者的映射,并通过磨损优化、垃圾回收来优化寿命;在HHD中,由硬件的固件管理来进行简单的映射得到CHS(磁头柱面扇区)。

四、文件控制块(FCB)与文件操作 #
4.1 FCB(File Control Block) #
操作系统为管理文件而设置的数据结构,存放管理文件所需的所有信息(即文件元数据)。
常用属性:文件名、文件号、保护/口令、创建者/拥有者、文件地址(提供LBA的信息)、文件大小、文件类型、创建/修改/访问时间、各种标志(只读、隐藏、系统、归档、临时、锁等)
4.2 文件基本操作 #
| 操作 | 说明 |
|---|---|
| create / delete | 建立 / 删除文件 |
| open / close | 打开 / 关闭文件(访问前必须打开) |
| read / write | 读写文件 |
| append / seek | 追加数据 / 定位读写指针 |
| get/set attributes | 读取/设置文件属性 |
| rename | 重命名 |
- 创建文件:建立文件的FCB(目录项),分配存储空间
- 打开文件:根据文件名在文件目录中检索,并将该文件的目录项(FCB)读入内存,建立相应的数据结构(用户打开文件表、系统打开文件表),为后续的文件操作做好准备。更细节一点,根据文件路径名查目录得到目录项(或i节点号),根据文件号查系统打开文件表,查看文件是否已经被打开,若是则引用计数加1,若否则将目录项(或i节点)等信息填入到系统打开文件表空表项中,引用计数置为1;根据打开方式、共享说明和用户身份检查访问合法性;在用户打开文件表中取一个空表项,填写打开方式等,并指向系统打开文件表对应表项。
- 指针定位:由fd查用户打开文件表找到对应入口,将表中文件读写指针位置设为新指针位置。
- 读文件:根据fd找到FCB,确定读的合法性;获取文件的逻辑块地址LBA;申请缓冲区,启动磁盘IO操作把磁盘块中的信息读入缓冲区,再传送到指定的内存区
五、文件目录 #
5.1 文件目录、目录项与目录文件 #
- 文件目录:将所有文件的管理信息组织在一起,统一管理每个文件的信息
- 目录文件:将文件目录以文件形式存放在磁盘上,内容由目录项组成,是典型的记录式文件。所以,在磁盘上,目录文件的形式就是一个一个的目录项组合起来的。
- 目录项:构成目录文件的基本单元,通常包含 FCB(或 FCB 的关键字段)
为确保映射的完整性,只允许内核修改目录,应用程序通过系统调用(如mkdir)访问目录。
目录文件的内容就是一个目录项的数组,每个目录项是一个定长结构,在UNIX中包含文件名、i节点号等等,在FAT32中包含文件名、起始簇号、属性、大小等等,一个接着一个地填满磁盘块。所以,目录文件 = 目录项序列,这和普通文件 = 字节序列是一个道理。
目录文件和普通文件的分配规则是一样的,都是按块分配,最小1块,可以多块。块是存储分配的最小单位。对于目录文件,其分配的一块中都是一系列定长的结构体:目录项构成,一般最少包含.和..这两个目录项。
目录项是"索引卡片",FCB 是"完整档案"。目录项的内容是文件名+指向FCB的指针,存在目录文件的数据块里;FCB的内容是文件的所有管理信息如文件大小、物理地址等,存在inode区或目录项本身。
在早期的FAT模式中,目录项 = FCB。缺点就是目录项很大,查找的时候要把大块数据全部读进内存。在目录项中有文件名用于查找、起始簇号用于提供文件地址信息等等。在后来的UNIX模式中,把FCB拆成了两半:一部分是符号目录项,包含文件名和inode号;另一部分是基本目录项,包含FCB的其余内容。优点是目录文件里只存轻量级的索引卡片,查找时读入内存的数据更小。完整的FCB按需从inode区读取。
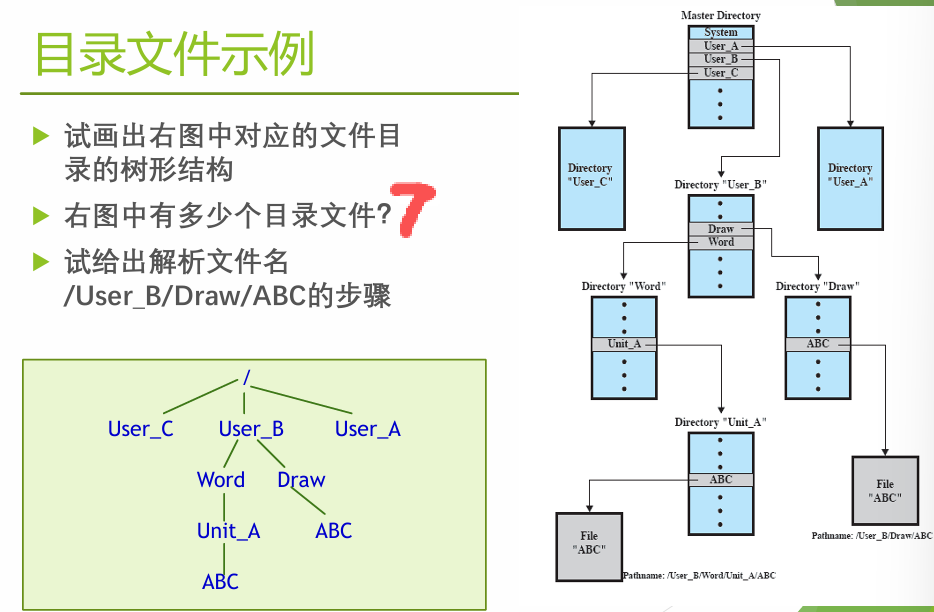
5.2 树形目录结构 #
- 从根目录开始的绝对路径,或从当前目录开始的相对路径
- 每个进程有一个当前目录(工作目录),可改变
- 典型目录操作:create、delete、opendir、closedir、readdir、rename、link、unlink
5.3 目录检索 #
访问一个文件分两步骤:
- 目录检索:按文件名查找目录项/FCB(文件名解析)
- 文件寻址:根据 FCB 中文件物理地址信息,计算目标记录在介质上的地址
5.4 目录项分解法(提高检索速度) #
将 FCB 分成两部分:
| 部分 | 内容 |
|---|---|
| 符号目录项 | 文件名 + 文件号(i 节点号) |
| 基本目录项 | 除文件名外的所有字段 |
例子:FCB 48 字节,物理块 512 字节,128 个目录项
- 分解前:平均访盘 7 次
- 分解后:平均访盘 2.5 次
分解前:FCB 全部 48 字节全放在目录文件里。
- 一块 512B 只能放 10 个目录项(512 / 48 = 10,剩 32B 浪费)
- 128 个目录项 = 需 13 块
- 线性查找,平均读一半的块 → 13 / 2 ≈ 7 次
分解后:FCB 拆成符号目录项(6B 文件名 + 2B i 节点号 = 8B)和基本目录项(42B)。
- 符号目录文件:一块放 64 个(512 / 8 = 64),128 个条目只需 2 块,平均读 1 块
- 基本目录文件:一块放 12 个(512 / 42 ≈ 12),128 个条目需 11 块。但不需要线性搜索——符号目录项里已经拿到了文件号,直接在基本目录文件里定位到对应条目所在的块(摊下来平均约 1.5 次,因为 42B 条目可能跨块边界)
平均访盘 = 1 + 1.5 = 2.5 次,从 7 次降到 2.5 次。关键不在于算得更少,而在于符号目录文件瘦身后查找快得多,基本目录文件只需要随机访问一次。
六、文件系统的实现 #
实现文件系统需要考虑磁盘与内存中的内容布局
6.1 磁盘上的文件系统布局 #
UNIX 布局 #
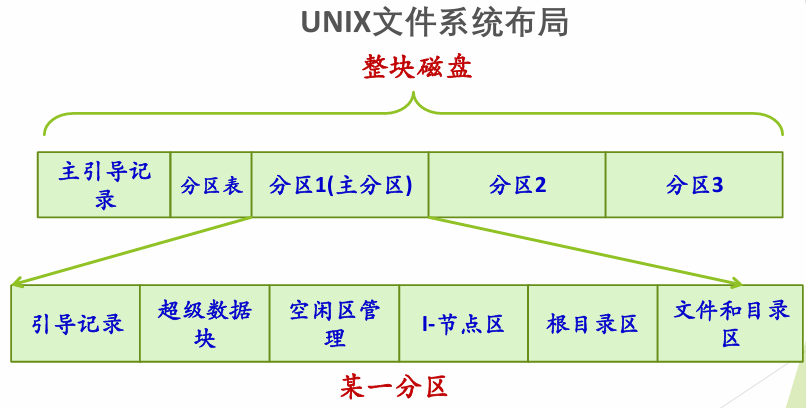
每一个分区内是一个文件系统
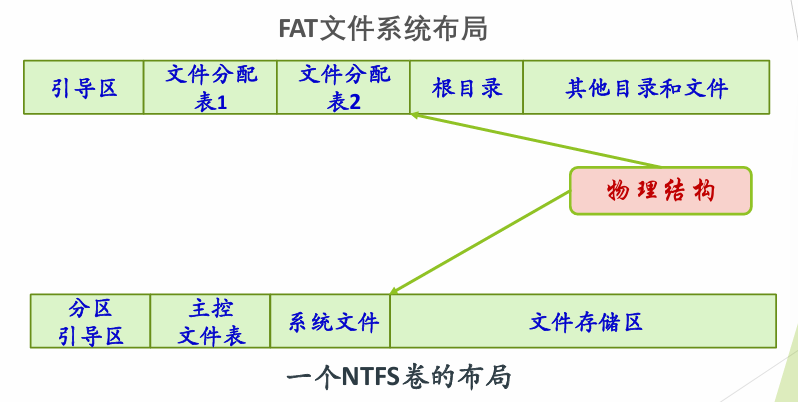
FAT 布局 #
6.2 文件的物理结构(LBA的组织方式) #
核心问题:文件在物理介质上的存放方式——分配给文件的LBA的位置和顺序。 要考虑的问题:存储效率:外部碎片等;读写性能:访问速度
6.2.1 连续结构 #
文件信息存放在若干连续的LBA中。
| 优点 | 缺点 |
|---|---|
| 简单、高效 | 文件不能动态增长(需预留空间) |
| 支持顺序和随机存取 | 不利于插入和删除 |
| 寻道次数最少 | 外部碎片问题 |
FCB 中记录文件地址的LBA:起始LBA块号 + 文件长度(块数)。
6.2.2 链接结构 #
文件信息存放在若干不连续的LBA中,各块之间通过指针连接。
| 优点 | 缺点 |
|---|---|
| 无外部碎片 | 存取速度慢,不适于随机存取 |
| 利于文件插入删除和动态扩充 | 可靠性问题(链接指针出错) |
| - | 链接指针占用空间、更多寻道 |
FCB 中记录:首块 LBA 块号。(虽然是一个链表,但是也不需要遍历全部的块:下一个 LBA 的位置已经在该 LBA 中存了)
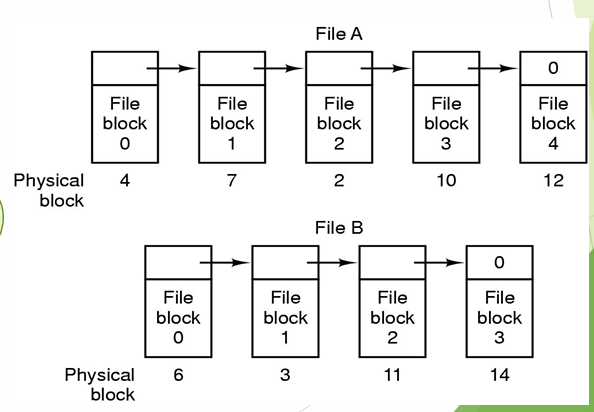
这样有一些问题:纯链接有两个致命缺陷,(1) 访问文件第 N 块必须从第 1 块开始逐个读,无法随机存取;(2) 指针和数据混在一起,指针损坏则整个链断掉。FAT(文件分配表)则是把链表的指针和数据分离,将所有"下一块号"指针集中搬到一张独立的表里(FAT),数据块只放数据。
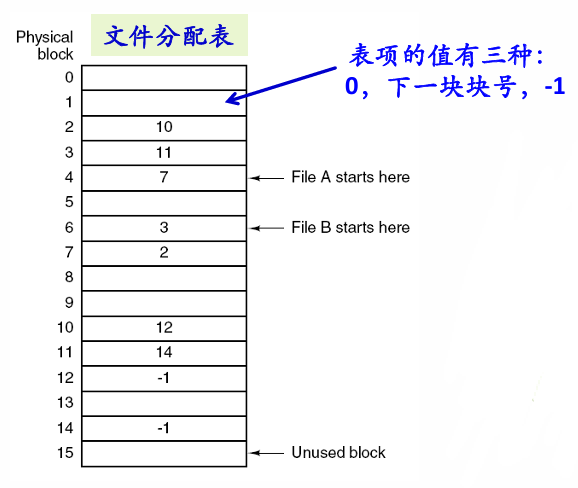
纯链接:
块4 [数据 + 指针→7] → 块7 [数据 + 指针→2] → 块2 [数据 + 指针→文件尾]
↑ 指针和数据混在一起,必须读磁盘才能跟随链
FAT:
磁盘上: 块4 [纯数据] 块7 [纯数据] 块2 [纯数据]
内存中: FAT 表(数组,下标 = 当前块号,值 = 下一块号)
FAT[2] = -1 (文件尾)
FAT[4] = 7 ← FCB 记录首块号 4,查 FAT[4] 得到下一块 7
FAT[7] = 2 ← 查 FAT[7] 得到 2
……FAT这样的好处是,在运行时缓存在内存里,要找到文件第 N 块,直接在内存里顺着 FAT 数 N 次就行,不需要读磁盘。随机存取成为可能。而且 FAT 有两份拷贝(FAT1 + FAT2 互为备份),一份坏了还有另一份。
文件的起始块号从何处得到?从FCB中查找。
fat表中可不可以理解为从fcb中找到第一个LBA然后从表中读,不断找到下一个LBA;然后os就能用LBA去找到对应的PBA。也就是说,fat存的都是LBA的值?
对,理解完全正确。
FAT 表就是一个以 LBA 为索引、以 LBA 为值的数组:
FAT[当前LBA] = 下一个LBA
OS 从头到尾只跟 LBA 打交道。LBA→PBA的转换在下面由磁盘固件(HDD)或 FTL(SSD)完成,OS完全不知道也不关心。这正好接回 3.4 节说的——LBA 是 OS 和存储设备之间的接口约定,FAT 表全程只存 LBA。
6.2.3 索引结构 #
系统为每个文件建立一个索引表,将文件占用的块号存放在一个索引表中。一个索引表就是磁盘块地址数组,其中第i个条目指 向文件的第i块。
| 优点 | 缺点 |
|---|---|
| 保持链接结构的优点,又解决随机存取问题 | 较多寻道 |
| 支持动态增长、插入删除 | 索引表本身占用空间 |
FCB 中记录:索引表所在块号。
索引表过大的解决方案:
- 链接方式: 多个索引表盘块之间链接
- 多级索引: 二级索引 → 一级索引 → 数据块,将文件的索引表(二级索引)的地址放在另一个索引表(一级索引)中
- 综合模式: 直接索引 + 间接索引结合 (顶级索引表的字段可以是一个放数据的LBA,也可以是次级索引表的LBA)
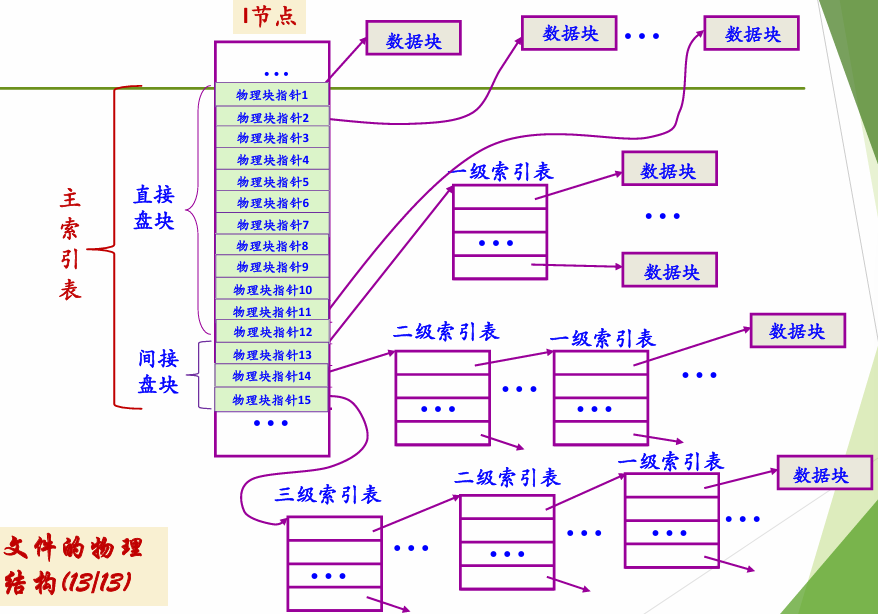
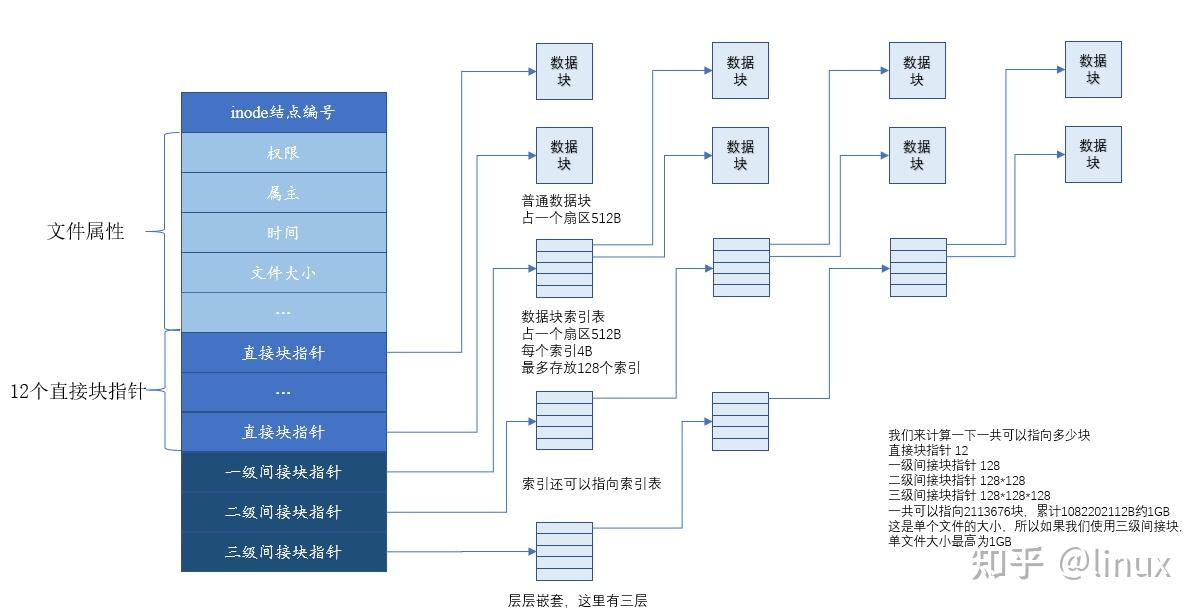
6.2.4 UNIX 多级索引(综合模式) #
每个文件的 i 节点中有 15 个索引项:
索引 0~11 → 直接寻址(12 个数据块)
索引 12 → 一级间接索引(→ 256 个数据块)
索引 13 → 二级间接索引(→ 256×256 个数据块)
索引 14 → 三级间接索引(→ 256³ 个数据块)小文件直接用直接寻址,大文件逐级扩展,兼顾效率和容量。
6.3 目录文件的组织方式 #
目录项的组织方式:
- 顺序表:简单,查找需线性搜索
- 散列表:根据文件名计算散列值定位,查找速度快
- B 树 / B+ 树:NTFS 采用,大目录下依然高效
6.4 文件共享 #
文件共享是指一个文件被多个用户或进程使用。多用户系统中的文件共享是很必要的。一种实现方式是文件别名:
| 方式 | 原理 | 特点 |
|---|---|---|
| 硬链接 | 多个目录项指向同一个 i 节点 | 共享计数归零才删除文件;不能跨文件系统 |
| 软链接(符号链接) | 建立特殊类型文件,内容为共享文件路径名 | 可跨文件系统甚至跨网络;系统开销大 |
硬链接的实现:
- 在FCB中直接给出文件地址,但是这样可能导致同步问题。
- 目录项指向i节点,i节点中增加一个共享计数,每次创建硬链接共享计数 +1,删除硬链接共享计数 -1,共享计数为0时才真正删除文件。
软链接的实现:建立一种特殊类型(Link)的文件,其内容是要共享的文件路径名。访问软链接时,系统会自动解析路径名,找到目标文件进行访问。只有真正的文件所有者才有指向i节点的指针。可以建立任意的别名关系,甚至原文件是在其他计算机上。问题:系统开销大;目录结构可能形成环状;优势:计算机网络环境下可用
6.5 磁盘空间管理 #
空闲空间管理方法 #
| 方法 | 说明 |
|---|---|
| 空闲块位图 | 每块对应一位,0=空闲/1=已分配;块号 = 字号×字长 + 位号 |
| 空闲块表 | 所有空闲块号记录在一个表中 |
| 空闲块链表 | 所有空闲块链成链表 |
| 成组链接法 | UNIX 采用——将空闲块分组,每组首块记录下一组信息 |
UNIX 成组链接法 #
- 专用块记录当前空闲块组:
[空闲块数 N, 空闲块号1, …, 空闲块号N] - 分配时:从专用块取块;若剩最后一块,该块中存着下一组信息
- 回收时:若当前组不满,填入;若满,将当前组信息写入回收块,回收块成为新组
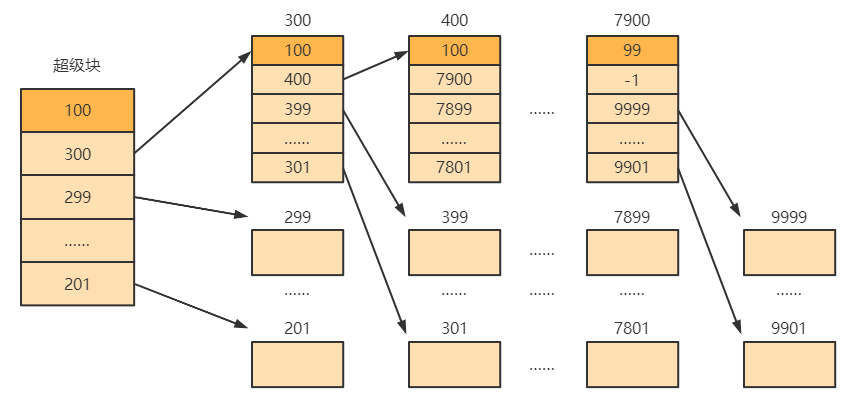
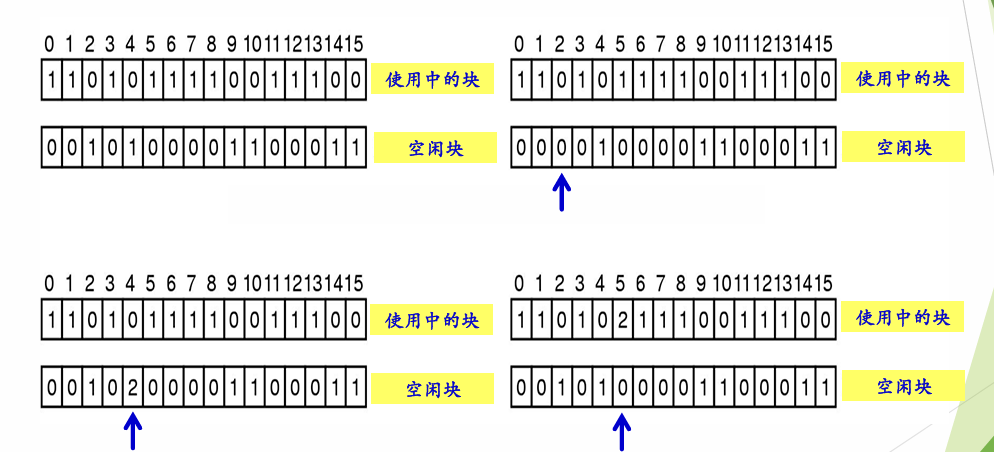
文件卷的目录区中专门用一个磁盘块作为“专用块”,当系统启动时需要将专用块读入内存,并且要保证内存与外存中的“专用块”数据一致。专用块的第一个元素是下一组空闲盘块数 n,接下来跟着的是 n 个空闲块号。其中第一个空闲块指向保存下一个超级块的信息,仍然是空闲盘块数 n 和 n 个空闲块号。直到最后一个专用块的信息没有后续的空闲块号,它的第一个空闲块号为特殊值例如 -1。
当需要 i 个空闲块时,检查第一个分组的块数是否足够,如果 i < n 是足够的,就分配第一个分组中的 i 个空闲块,并修改相应数据。例如上图的成组链接,若需要 5 个空闲块,可以分配 201 ~ 205 号空闲块,并修改专用块的空闲块数量为 95。
如果 i ≥ n 刚好或不足够,则需要分配第一个分组中的全部空闲块,由于第一个空闲块存放了再下一组的信息,因此号块的数据需要复制到专用块中。例如上图的成组链接,若再需要 95 个空闲块,可以分配 206 ~ 300 号空闲块,由于 300 号块内存放了再下一组的信息,因此 300 号块的数据需要复制到专用块中。
6.6 内存中的数据结构(打开文件管理) #
UNIX 的文件打开结构 #
| 结构 | 范围 | 内容 |
|---|---|---|
| 用户打开文件表 | 每个进程一个 | 文件描述符、读写指针、i 节点指针、打开方式 → 位于 PCB 中 |
| 系统打开文件表 | 整个系统一个 | FCB(i 节点) 信息、引用计数、修改标志 |
打开文件流程:
- 根据路径名查目录,找到 i 节点号
- 查系统打开文件表:若已打开 → 共享计数 +1;否则将 i 节点填入
- 检查访问权限
- 在用户打开文件表中取空表项,指向系统打开文件表
- 返回文件描述符(fd)——非负整数,用于后续操作
七、文件系统实例 #
对于磁盘而言,其分区结构是:
+-------+-----------+-----------+-----------+-------+
| MBR | 文件系统1 | 文件系统2 | 文件系统3 | 其他分区 |
+-------+-----------+-----------+-----------+-------+MBR(主引导记录,LBA 0)是磁盘分区表的载体,跟文件系统无关——它告诉你磁盘分了几个区、每个区从哪开始到哪结束,负责引导 BIOS 找到活动分区并加载该分区的引导扇区。
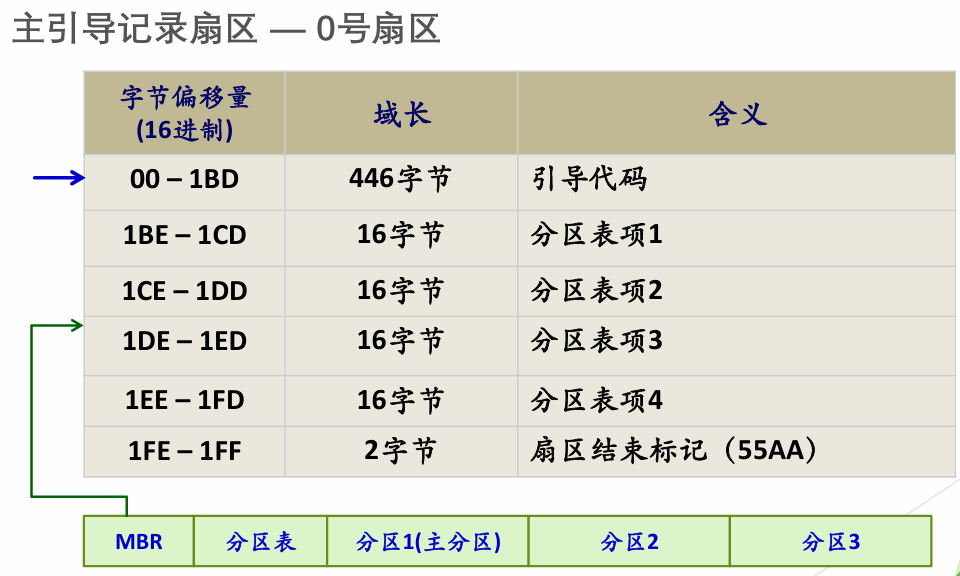
此处来源:计算机是如何启动的? “主引导记录"只有512个字节,放不了太多东西。它的主要作用是,告诉计算机到硬盘的哪一个位置去找操作系统。
主引导记录由三个部分组成:
(1) 第1-446字节:调用操作系统的机器码。
(2) 第447-510字节:分区表(Partition table)。
(3) 第511-512字节:主引导记录签名(0x55和0xAA)。
其中,第二部分"分区表"的作用,是将硬盘分成若干个区。考虑到每个区可以安装不同的操作系统,“主引导记录"因此必须知道将控制权转交给哪个区。分区表的长度只有64个字节,里面又分成四项,每项16个字节。所以,一个硬盘最多只能分四个一级分区,又叫做"主分区”。
计算机在启动的时候,BIOS回把控制器转交给排在第一位的储存设备。这时,计算机读取该设备的第一个扇区,也就是读取最前面的512个字节。如果这512个字节的最后两个字节是0x55和0xAA,表明这个设备可以用于启动;如果不是,表明设备不能用于启动,控制权于是被转交给"启动顺序"中的下一个设备。MBR就是这512字节。
⭐UNIX 文件系统 #
UNIX的文件系统中的文件以索引结构来组织。文件系统为每个文件的所有块建立了一个索引表,索引表就是块地址数组,每个数组元素是块的地址,每个数组元素的下标是文件块的索引,第n个数组元素指向文件中的第n个块。
包含这个索引表的索引结构成为inode,即index node,索引节点,用来索引一个文件的所有块。在UNIX系统中,一个文件必须对应一个inode,磁盘中有多少文件就有多少个inode。
- inode 结构
inode包含了文件的属性,12个直接数据块指针,和3个间接块指针。对于数据块索引表,也是存在磁盘上。
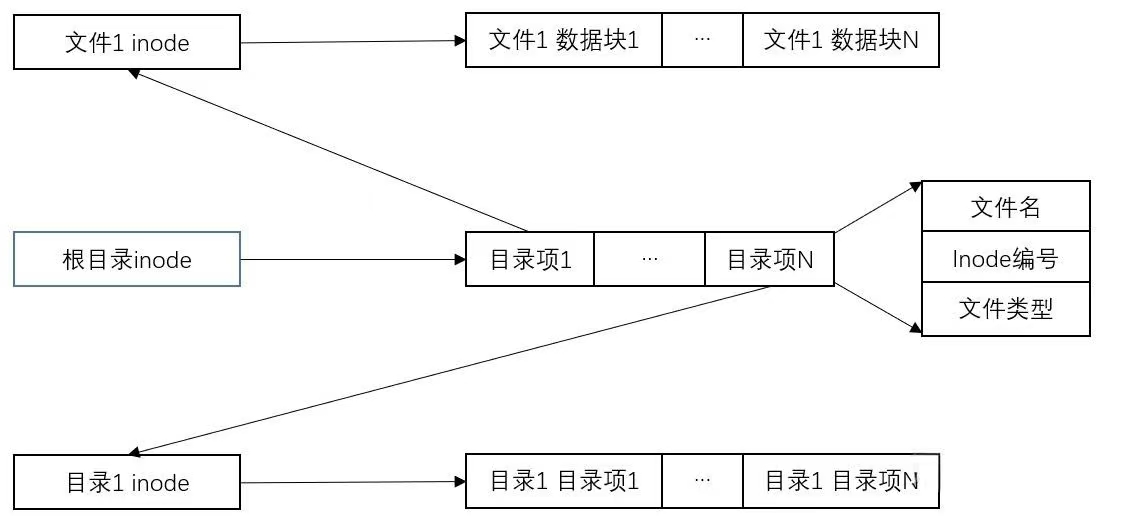
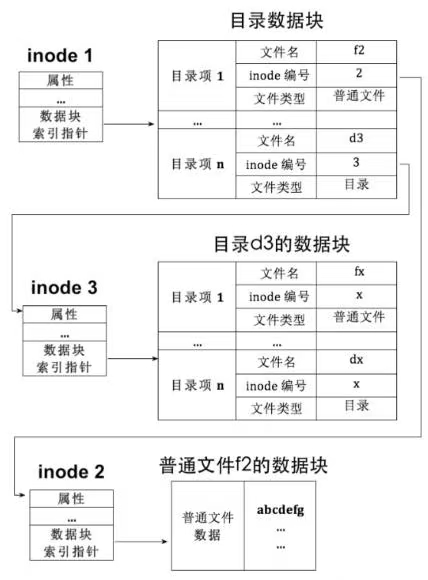
- 目录项
inode用来表示文件,不管是普通文件还是目录文件。文件系统区分这两种文件的方式并不依赖于inode,inode是无法决定的,也是不必关心的。唯一的方式就是数据块本身的内容了。如果inode表示的是普通文件,这个inode指向的数据块中的内容就是普通文件自己的数据;如果表示的是目录文件,这个inode指向的数据块中的内容就是该目录下的目录项。在只考虑这两种文件的情况下,目录文件的数据块中,要么是普通文件的目录项,要么是目录文件的目录项。
可以认为,UNIX系统中的FCB就是inode,或者说FCB = inode + 目录项。目录项中包含了文件名和对应的inode号;inode中包含了文件的属性、文件地址信息、块指针等等。
- 超级块和文件系统布局
每个文件都有一个inode,所有的inode都放在inode数组中,这个数组在哪里?大小是多少?对于一个硬盘,每个分区都有自己的根目录,地址不统一,怎么找到根目录地址?
这时需要在某个固定地方去获取文件系统元信息的配置,这个地方就是超级块,超级块是保存文件系统元信息的元信息。下图是硬盘布局和其中一个UNIX分区的布局:
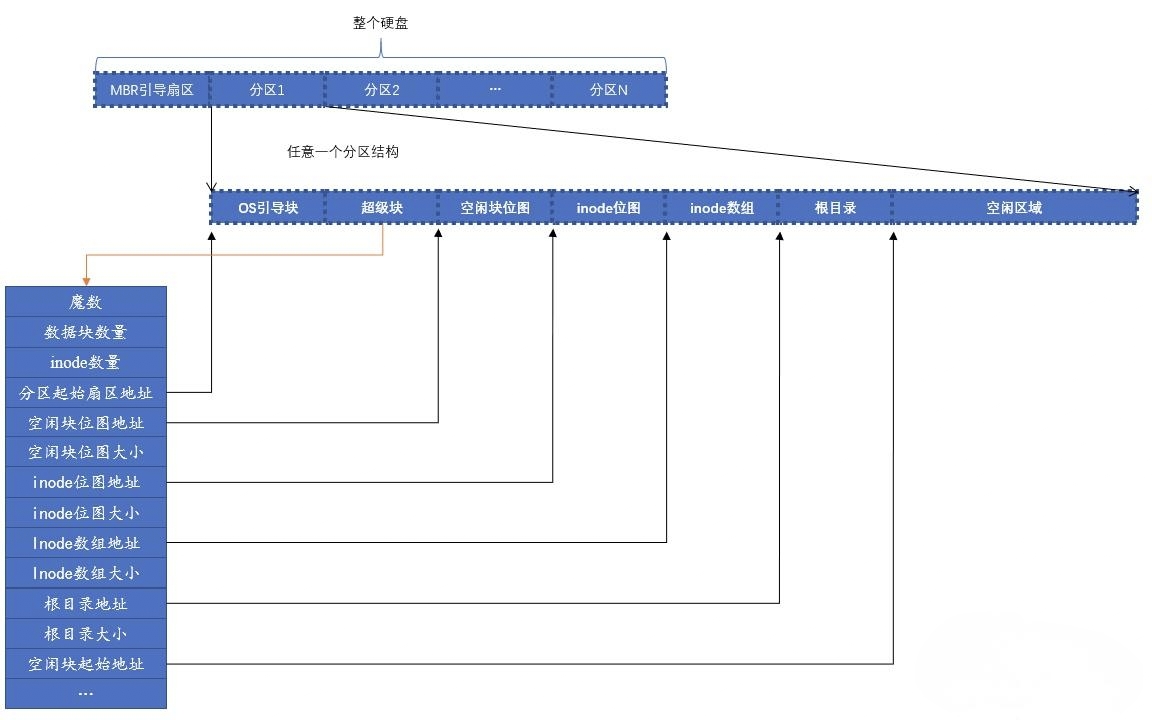
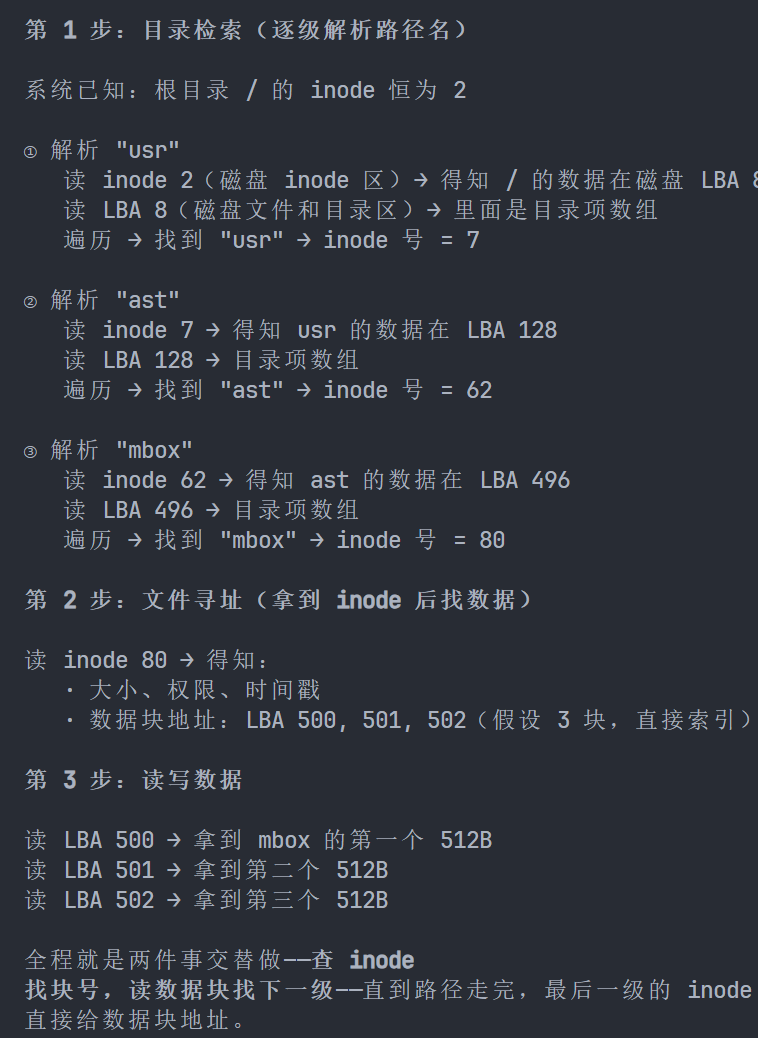
- 查找文件过程
给出一个文件名/user/ast/mbox,查询文件的流程:
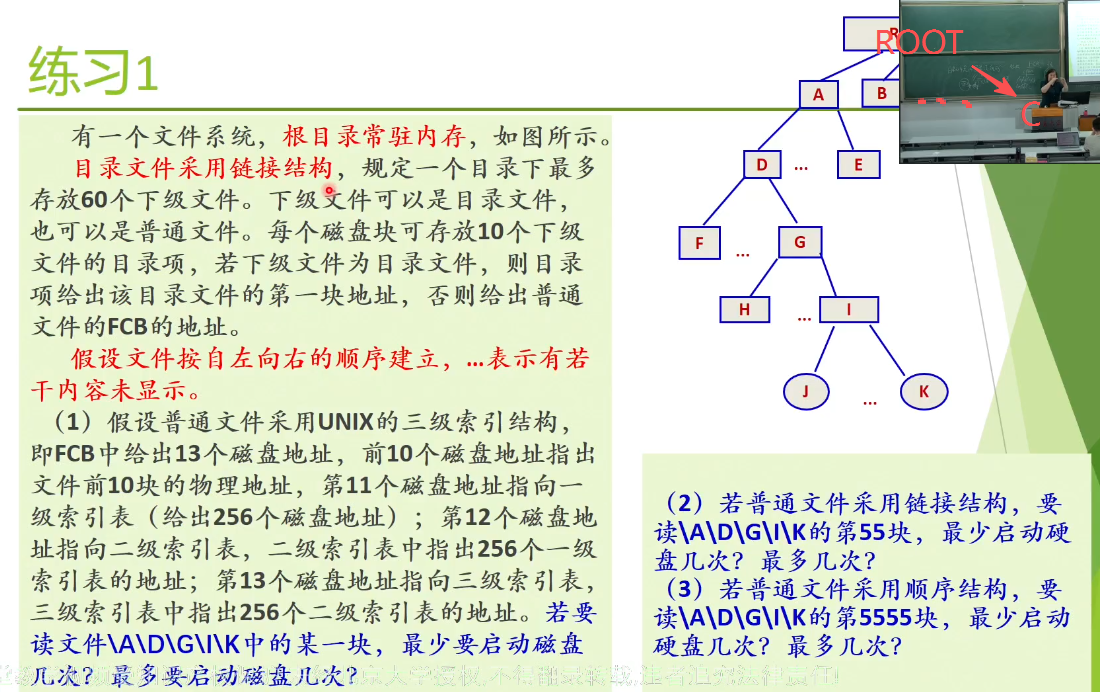
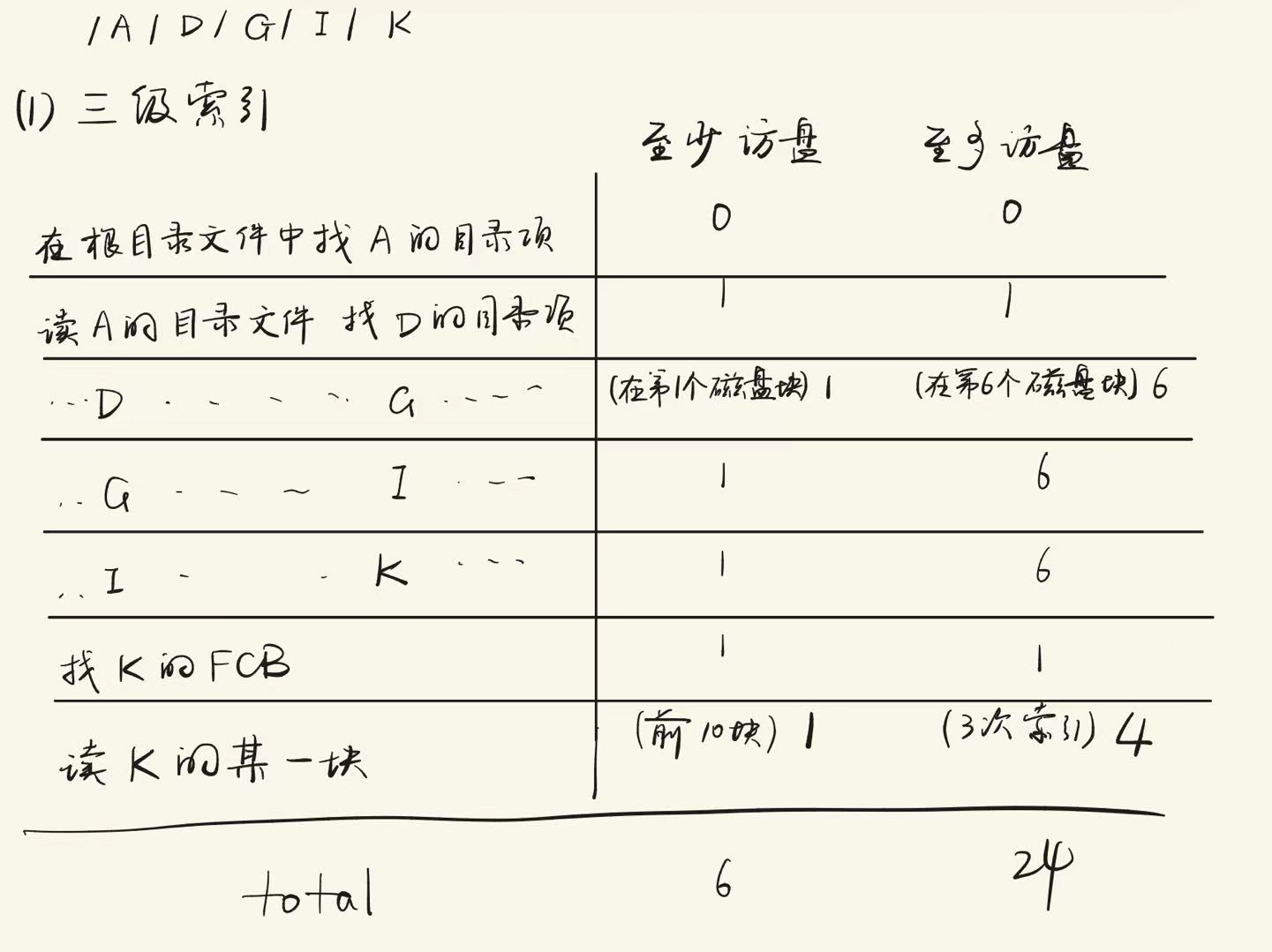
- 练习1
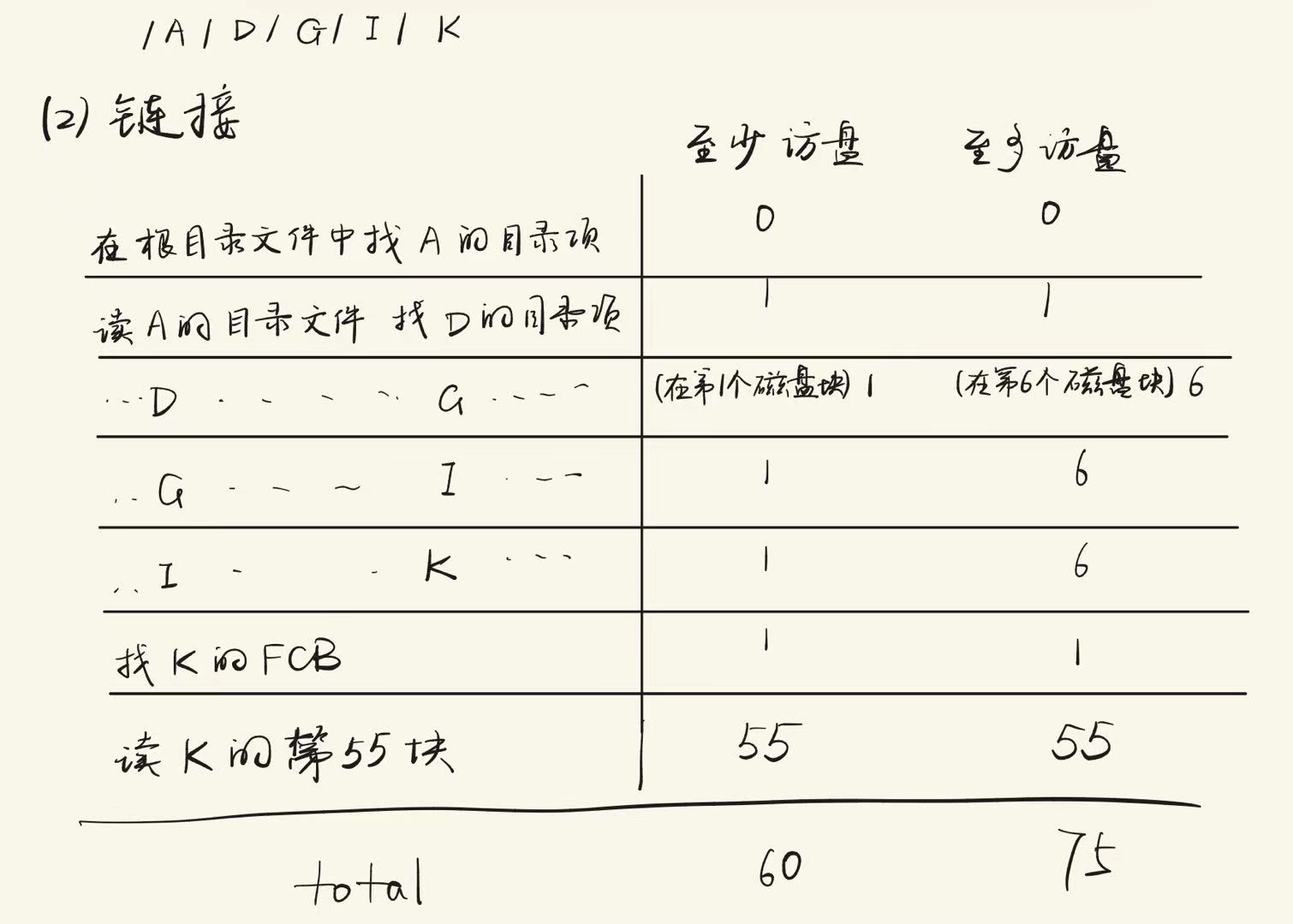
- 练习2
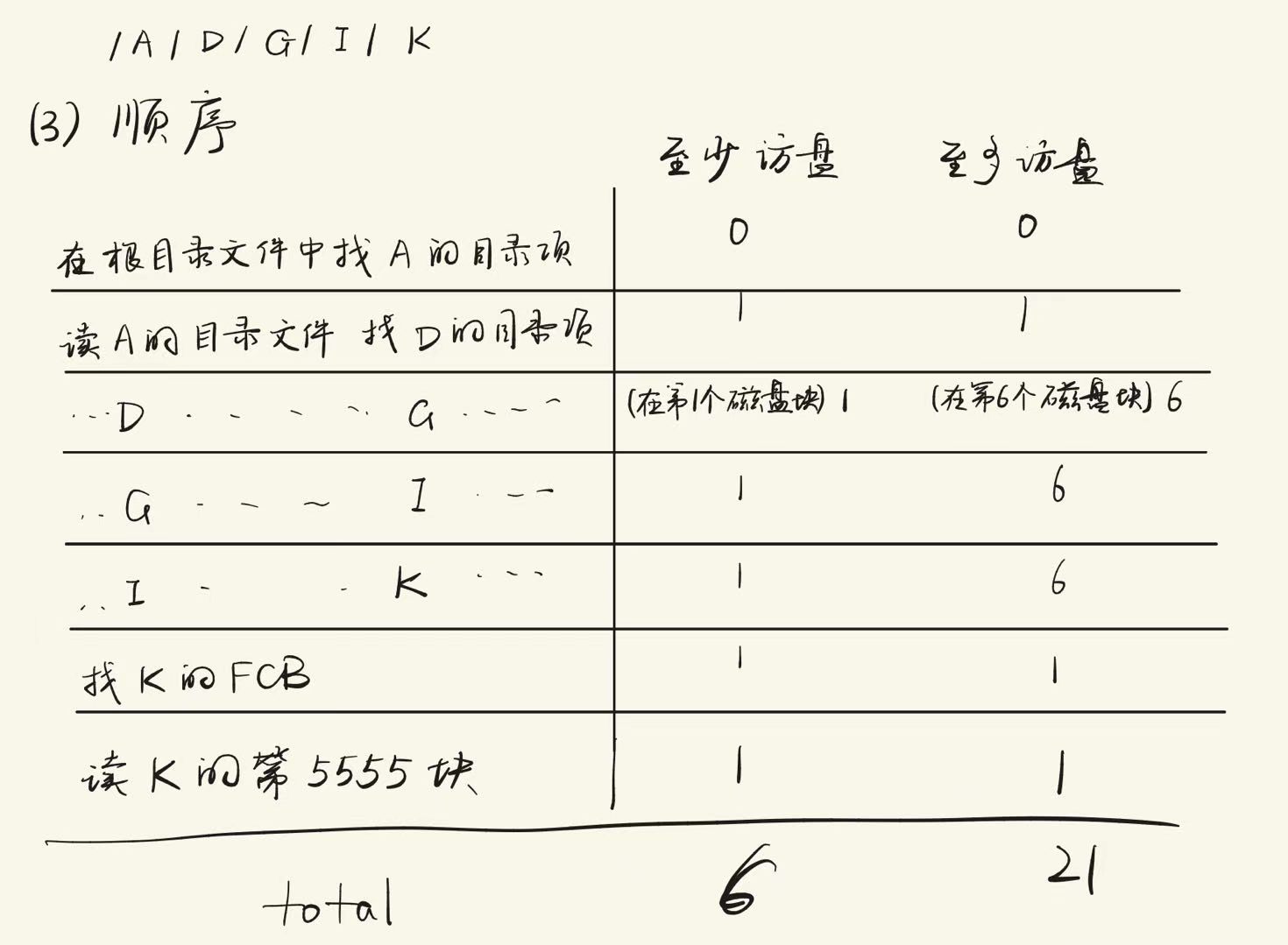
假设一块刚格式化好的磁盘大小是2M,每块为512字节,画出UNIX文件系统布局,和在经过如下操作后的布局。
操作序列:
\ mkdir A
A mkdir B
B create File1(4块)
\ mkdir C
\ mkdir D
C mkdir E
E create File2(16块)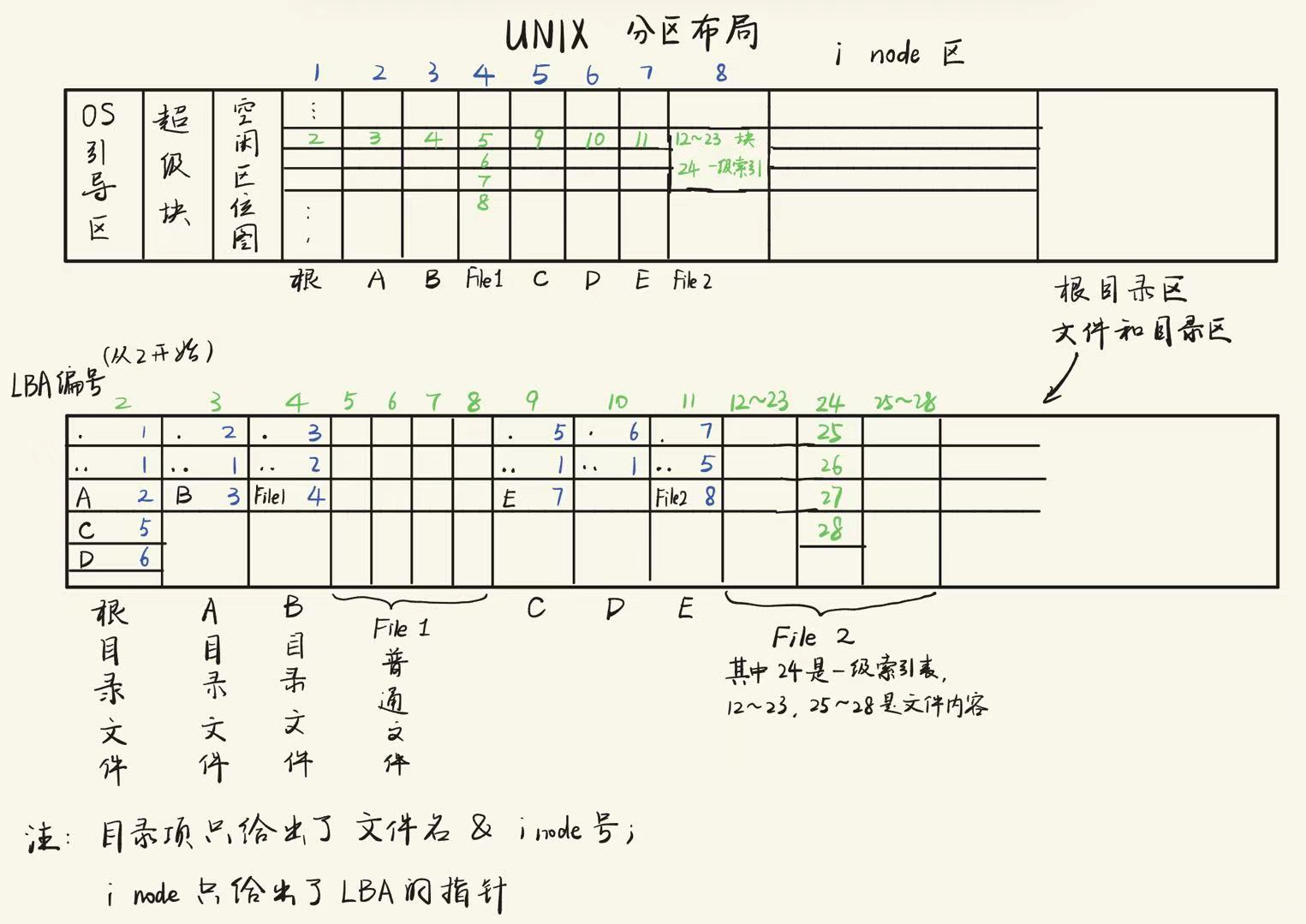
⭐FAT 文件系统 #
FAT文件系统中,FCB就是目录项,与UNIX不同。根目录大小固定。其分区布局是:
+-------+-----------+-----------+-----------+-------+
| 引导区 | 文件分配表1 | 文件分配表2 | 根目录区 | 数据区 |
+-------+-----------+-----------+-----------+-------+- 引导区
引导区有引导代码和其他元数据,这些其他元数据相当于UNIX的super block
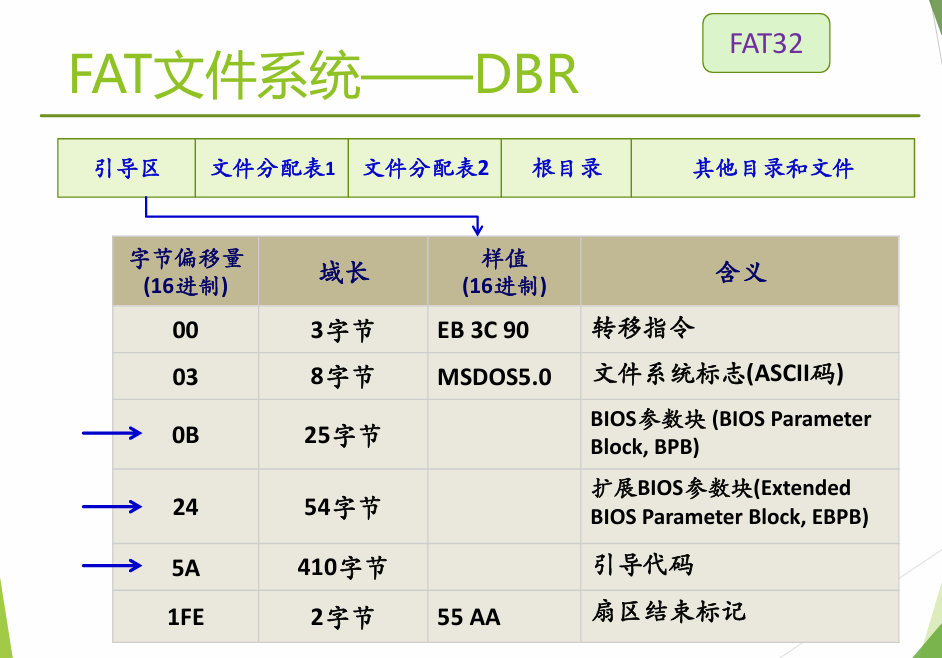
其中BIOS参数块中给出了每簇的扇区数、每扇区的字节数等信息,这些信息可以用来计算每簇的字节数,从而知道每个簇能存多少目录项(FAT16中一个目录项48字节,FAT32中一个目录项32字节)。FAT表的大小和位置也在引导区中给出。

- 文件分配表
FAT表可以看作是一个整数数组,每个整数代表数据区的一个簇号。
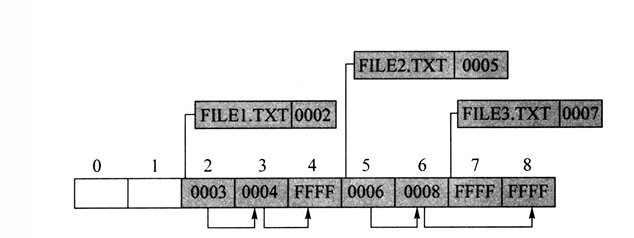
- 目录项
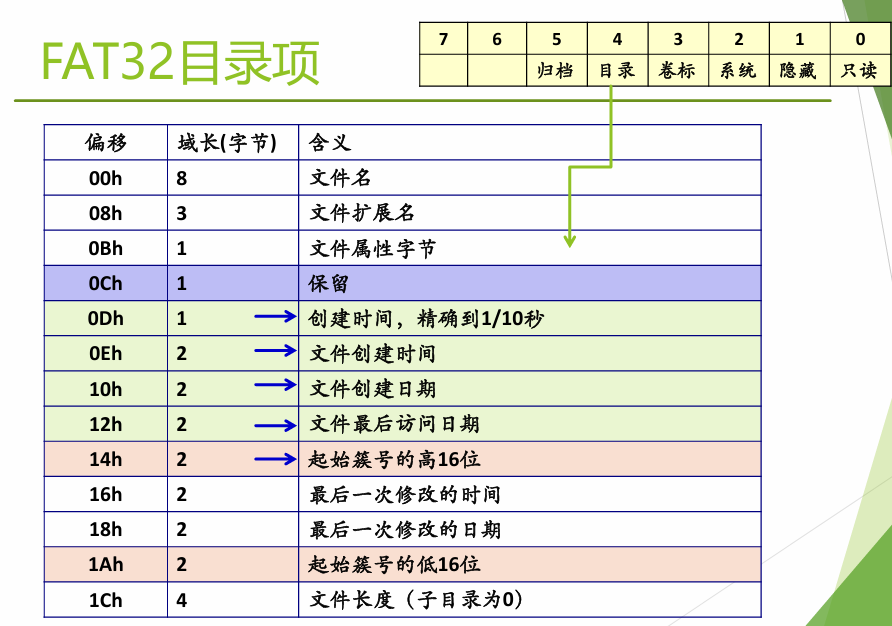
FAT32系统的目录项也是在数据区中以文件的形式存储的。每个目录项占用32字节,包含文件名、属性、起始簇号、文件大小、修改时间等信息。
下面是FAT16的目录项(FCB),可以发现只有修改的日期和时间,没有创建和查看的,会有安全问题;还有起始簇号。

在FAT32中目录项仍然是32字节,但是分为各种类型(包括:“.”目录项、“..”目录项、短文件名目录项、卷标项(根目录)、已删除目录项(第一字节为0xE5)、长文件名目录项等)。对于一个文件至少有俩目录项,即短和长文件名目录项。在短目录项中,把保留的10个字节做了使用,存储了文件的起始簇号的高 16 位(FAT16 中没有这个字段)。因此 FAT32 的短目录项仍然是 32 字节,但结构发生了变化。
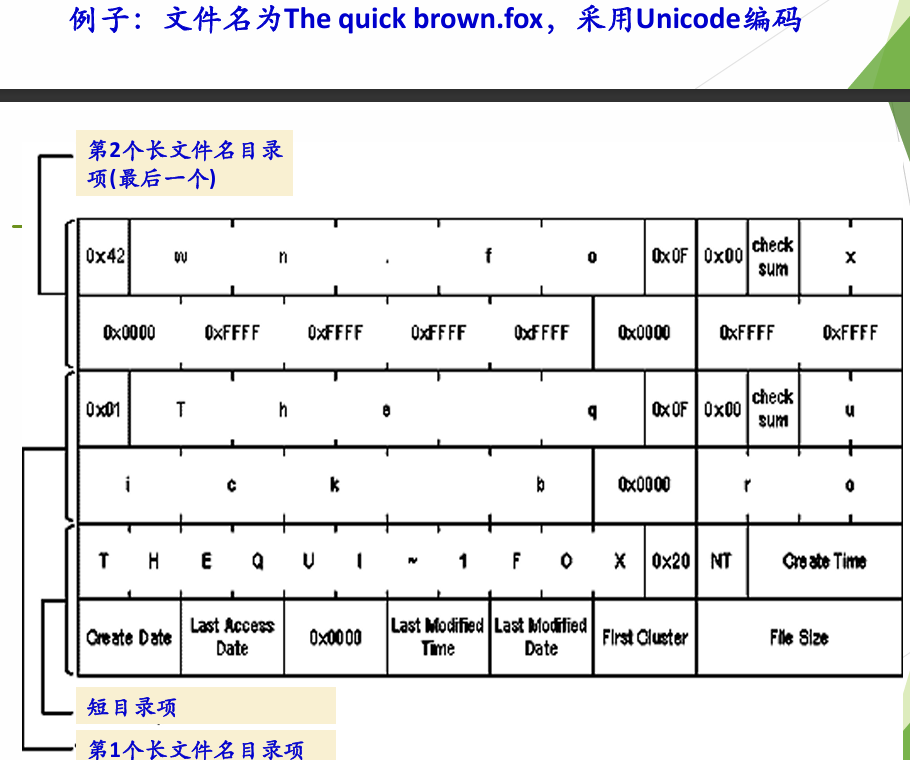
对于长文件名目录项,也是32字节,一个长文件名目录项可以存储 13 个 Unicode 字符(26 字节),剩余 6 字节用于其他信息(如序号、校验和等)。长文件名目录项与对应的短目录项通过序号和校验和关联起来,形成一个完整的文件名。
typedef struct long_name_entry {
uint8 order; // 序号:1~N,最后一项 | 0x40
wchar name1[5]; // 5 个 Unicode 字符
uint8 attr; // 必须是 0x0F(长文件名标记)
uint8 _type; // 保留
uint8 checksum; // 短文件名校验和
wchar name2[6]; // 6 个 Unicode 字符
uint16 _fst_clus_lo;// 文件起始簇号,常置0
wchar name3[2]; // 2 个 Unicode 字符
}
- 练习
假设一块刚格式化好的磁盘大小是2M,每块为512字节,画出FAT16文件系统布局,和在经过如下操作后的布局。
操作序列:
\ mkdir A
A mkdir B
B create File1(4块)
\ mkdir C
\ mkdir D
C mkdir E
E create File2(16块)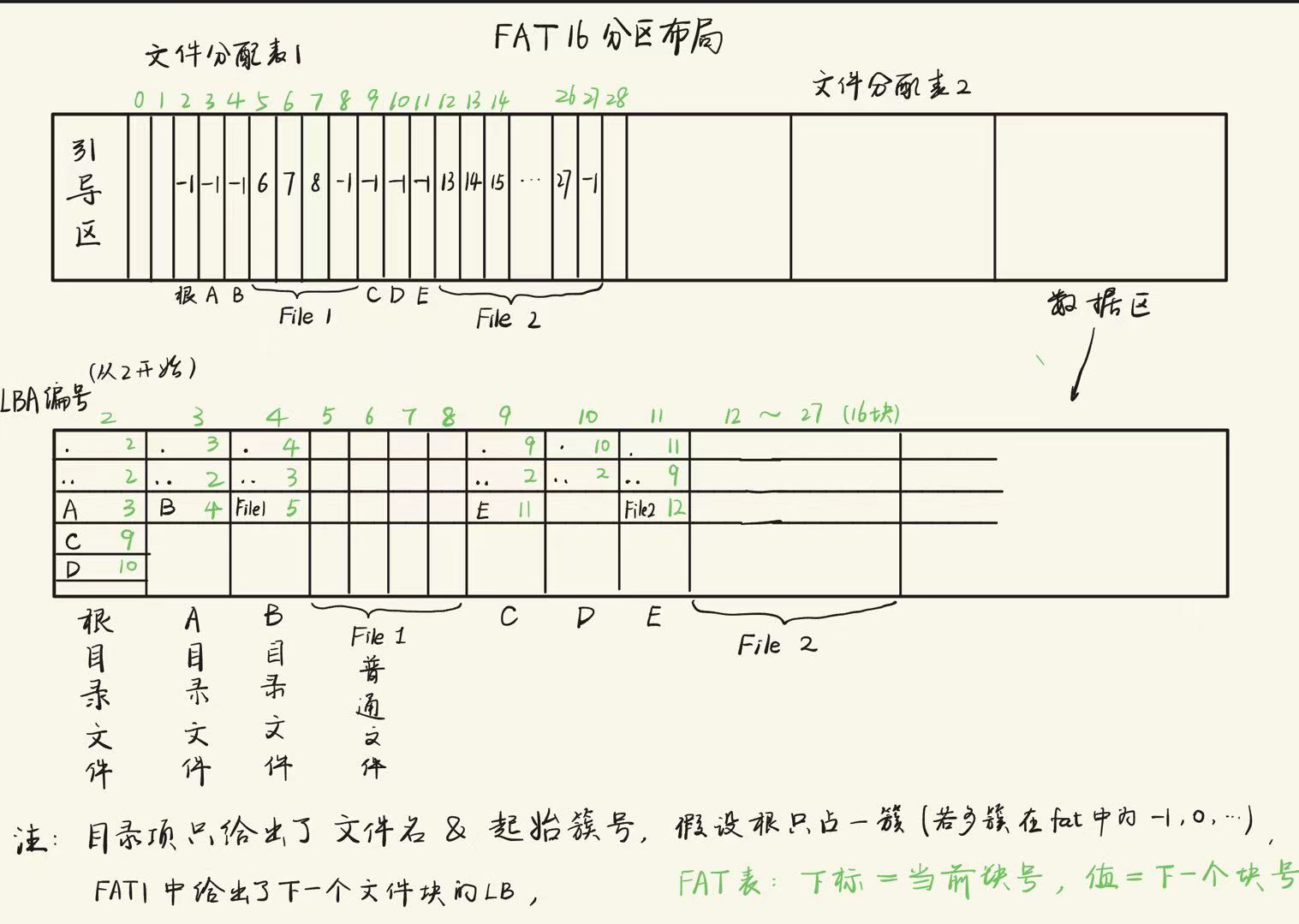
7.3 NTFS 文件系统 #
设计目标 #
可靠、高效、安全——原子事务、冗余存储、综合安全模型。
核心概念 #
| 概念 | 说明 |
|---|---|
| MFT(主控文件表) | NTFS 核心,以文件记录数组实现,每个文件/目录至少一个 MFT 项 |
| 文件引用号 | 64 位,文件号(48 位)+ 顺序号 |
| 属性 | 所有信息都是属性,文件内容是"未命名数据属性流” |
| 常驻属性 | 直接存放在 MFT 项中(标准信息、文件名等) |
| 非常驻属性 | 数据超出 MFT 项空间,存储在卷中其他簇 |
| VCN / LCN | VCN(虚拟簇号)用于文件内引用,LCN(逻辑簇号)用于卷内定位 |
| Run / Extent | 非常驻属性中的连续簇组,记录(VCN 起始, LCN 起始, 簇数) |
目录组织 #
- 目录中文件名按 B+ 树排序存储在索引缓冲区中
- 索引分配属性包含 VCN→LCN 的映射
NTFS 特色功能 #
- 数据压缩(以 16 个簇为压缩单元)
- 加密文件系统(EFS)
- 日志功能($LogFile)
- MFT 前 16 个项为元数据文件保留($Mft、$MftMirr、$LogFile、$Volume、$Bitmap 等)
八、挂载与虚拟文件系统 #
8.1 文件系统的挂载(Mount) #
将一个文件系统加入到另一个文件系统,用户提供:被挂载文件系统的根目录 + 挂载点。挂载后,被挂载文件系统的目录树出现在挂载点之下。
8.2 虚拟文件系统(VFS) #
VFS 是一个抽象层,为不同文件系统提供统一接口。用户程序以相同方式访问不同文件系统,屏蔽底层差异。
工作流程:
- VFS 对用户发起的文件系统调用进行路径解析
- 查找对应的目录项(dentry)和 inode
- 确定目标文件所在的真实文件系统
- 调用对应文件系统实现的具体方法
- 返回结果给用户
九、其他常用文件系统 #
| 文件系统 | 特点 |
|---|---|
| ext4 | Linux 默认,extents 分配(取代传统块映射,连续存储大文件时减少碎片,提升读写效率)、延迟分配、兼容 ext3/ext2 |
| XFS | 高性能日志文件系统,B+ 树元数据,大文件顺序读写优秀 |
| Btrfs | 基于b-tree,写时复制、快照、数据压缩、RAID、子卷管理 |
| ZFS / OpenZFS | 集文件系统与卷管理于一体,数据完整性校验、单卷最大 256ZB |
| APFS | Apple 为 SSD 优化的现代文件系统 |
| exFAT | 跨平台轻量,突破 FAT32 单文件 4GB 限制 |
| F2FS | 闪存友好,日志结构文件系统,为 NAND 闪存设计 |
十、文件系统的管理 #
- 文件系统的可靠性
可靠性:抵御和预防各种物理性破坏和人为性破坏的能力
策略?备份:
- 全量转储:定期将所有文件拷贝到后援存储器
- 增量转储:只转储修改过的文件,即两次备份之间的修改,减少系统开销
- 物理转储:从磁盘第0块开始,将所有磁盘块按序输出到磁带
- 逻辑转储:从一个或几个指定目录开始,递归地转储自给定日期后所有更改的文件和目录
- 文件系统一致性
这里强调的点是元数据的一致性,比如目录文件,其是元数据(因为是由目录项组成的)。
一致性问题产生的原因是,文件内容从磁盘块读入内存后,修改了内存中的数据,但还没有来得及写回磁盘,如果此时系统崩溃了,那么磁盘上的数据就不一致了。此时造成了不一致性。
解决方案:设计一个实用程序,当系统再次启动时,运行该程序,检查磁盘块和目录系统。
例子:UNIX一致性检查工作过程:两张表,每块对应一个表中的计数器,初值为0。表1:记录了每个磁盘块在文件中出现的次数;表2:记录了每个磁盘块在空闲块表中出现的次数。
现在考虑写入方式:
- 通写(write-through):每次修改都立即直接写回磁盘,性能较差,但数据一致性好。如
FAT文件系统。 - 延迟写(delayed write/lazy write)/回写(write back):修改先在内存中进行,定期或条件满足时批量写回磁盘,性能较好,但可能导致数据丢失,可恢复性较差。如
UNIX文件系统。 - 可恢复写(transaction log):为了考虑文件系统一致性和性能,引入了事务日志来实现文件系统的写入,既考虑安全性,又考虑速度性能,例:
NTFS
- 文件系统的安全性
安全性:保护文件系统免受未经授权访问和恶意攻击的能力。要提防数据丢失和入侵者。
如何实现?一是用户身份验证,二是访问控制(权限管理)。UNIX的权限模型是基于用户和组的读写执行权限(二级存取控制,一级是对用户分类,二级是对操作分类);NTFS则提供了更细粒度的访问控制列表(ACLs),支持复杂的权限设置。保证文件数据不能随意被访问。
- 数据恢复技术
数据恢复:从损坏或丢失的文件系统中恢复数据的技术。常用方法包括:
- 文件系统检查工具(如
fsck)修复文件系统结构 - 数据恢复软件扫描磁盘块,重建文件结构
- 备份恢复:从定期备份中恢复数据
十一、文件系统的性能 #
磁盘服务 → 其速度和可靠性成为系统性能和可靠性的主要瓶颈,设计文件系统应尽可能减少磁盘访问次数。提高文件系统性能的方法:
目录项(FCB)分解、当前目录、磁盘碎片整理、磁盘(块)高速缓存、磁盘调度、提前读取、合理分配磁盘空间、信息的优化分布、RAID技术… …
- 磁盘高速缓存
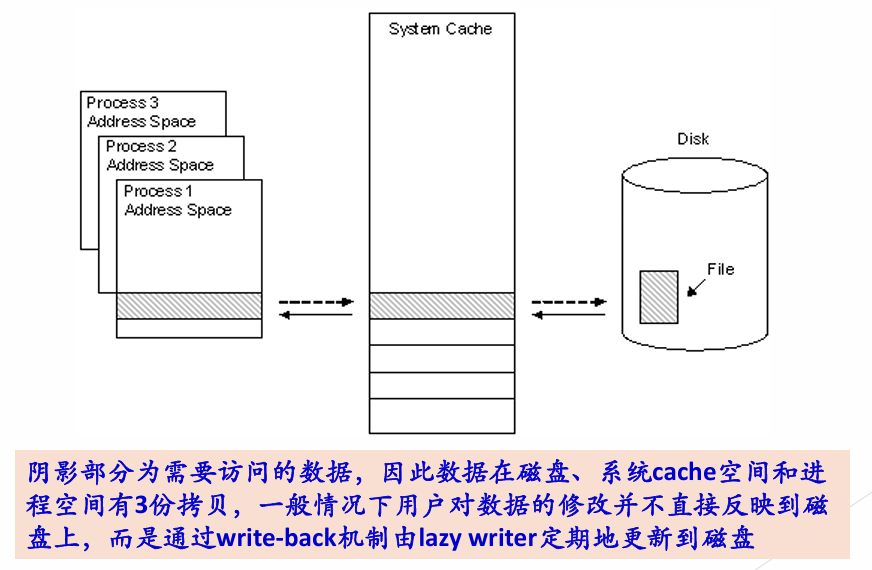
内存中为磁盘块设置的一个缓冲区,保存了磁盘中某些块的副本——磁盘高速缓存。
磁盘高速缓存(page cache)就是主存的一部分,位于内核地址空间。进程 read(fd, buf, n) → 内核查 page cache
- 命中 → 直接从 DRAM 拷到用户 buf → 不阻塞,立即返回
- 未中 → 进程 BLOCKED,发起磁盘 DMA 磁盘 → DRAM(page cache)→ 拷到用户 buf 中断通知,进程READY
所以 read() 不一定阻塞——数据恰好在 page cache 里就直接返回(比如刚被另一个进程读过、或者之前预读进来的),等磁盘的代价只有在 cache miss 。这和mmap()的原理类似,都是利用内存映射来实现文件访问的优化,mmap省了一层缓存。
目前学过的cache有:TLB, Block Cache, Web Page Cache等等
- Windows的文件访问方式
- 不使用文件缓冲:普通的方式,通过Windows提供的FlushFileBuffer函数实现
- 使用文件缓冲(Default):预读取。每次读取的块大小、缓冲区大小、置换方式;写回。写回时机选择、一致性问题,会定期更新磁盘上的数据(1s)。
- 异步模式:不再等待磁盘操作的完成,使处理器和I/O并发工作
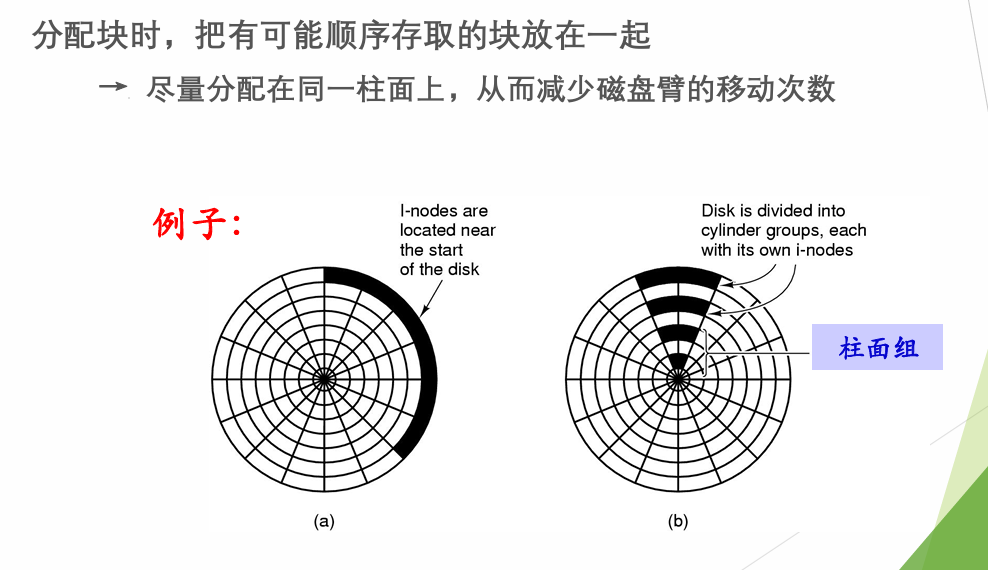
- 合理分配磁盘空间
在UNIX中查找文件需要在inode和目录项之间多次访问,在磁盘上分配文件时,尽量将文件的inode和目录项放在一起,减少磁盘臂的移动次数。
- 磁盘调度
比较合理的有:对于柱面采用最短寻道时间优先;对于同一个柱面用旋转调度算法
??????????? 1243/1342
621435
- RAID技术
设计时要考虑的是:磁盘存储系统 的 速度、容量、容错、数据灾难发生后的数据恢复。
解决方案:RAID(独立磁盘冗余阵列)(Redundant Arrays of Independent Disks)多块磁盘按照一定要求构成,操作系统则将它们看成一个独立的存储设备,这是高性能、容错、高可靠性的存储技术。
数据是如何组织存储的?通过把多个磁盘组织在一起,作为一个逻辑卷提供磁盘跨越功能。
- 通过把数据分成多个数据块,并行写入/读出多个磁盘,以提高数据传输率(数据分条stripe)(比如原来是100个块,现在分成10个块,分别写入10个磁盘,理论上速度提升10倍)
- 通过镜像(mirroring)或数据校验(data parity)操作,提高容错能力(冗余)和扩展性
参考文章: