PartC: 32×32矩阵转置按照8×8分块的miss数为什么是284? #
这里假设cache的参数设置是s = 5, E = 1, b = 5,总大小是1KB,也就是能装1024 / 4 = 256个int整型。
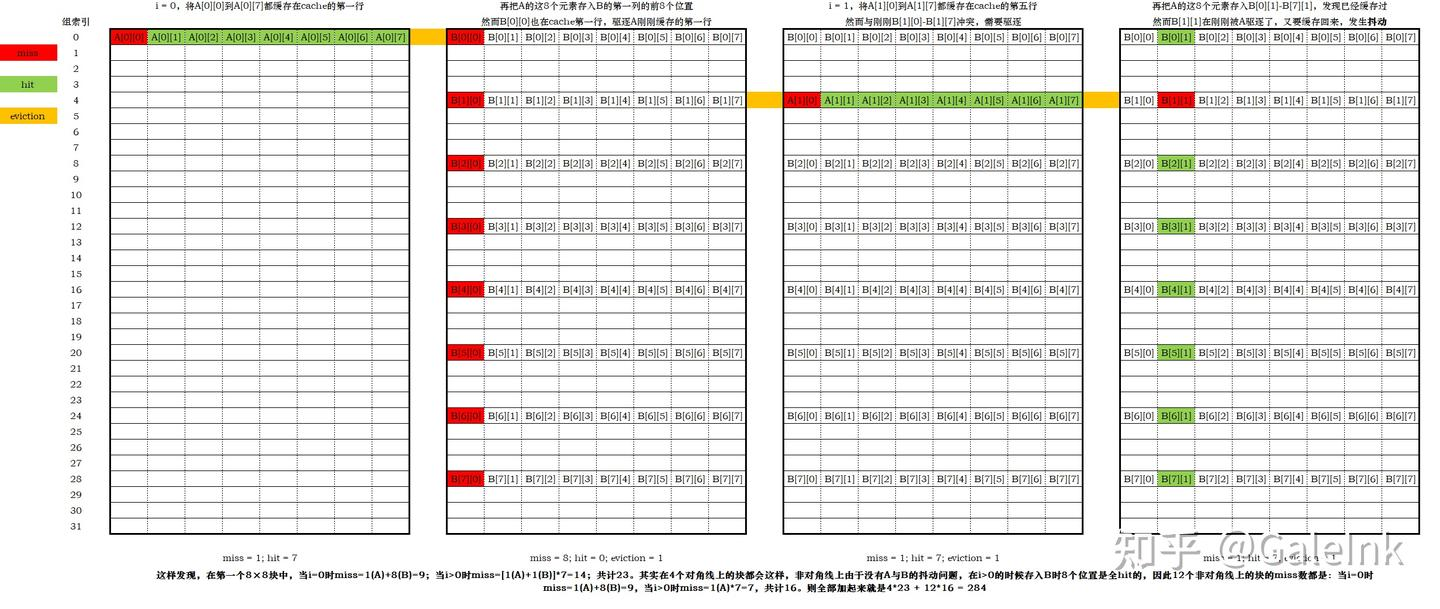
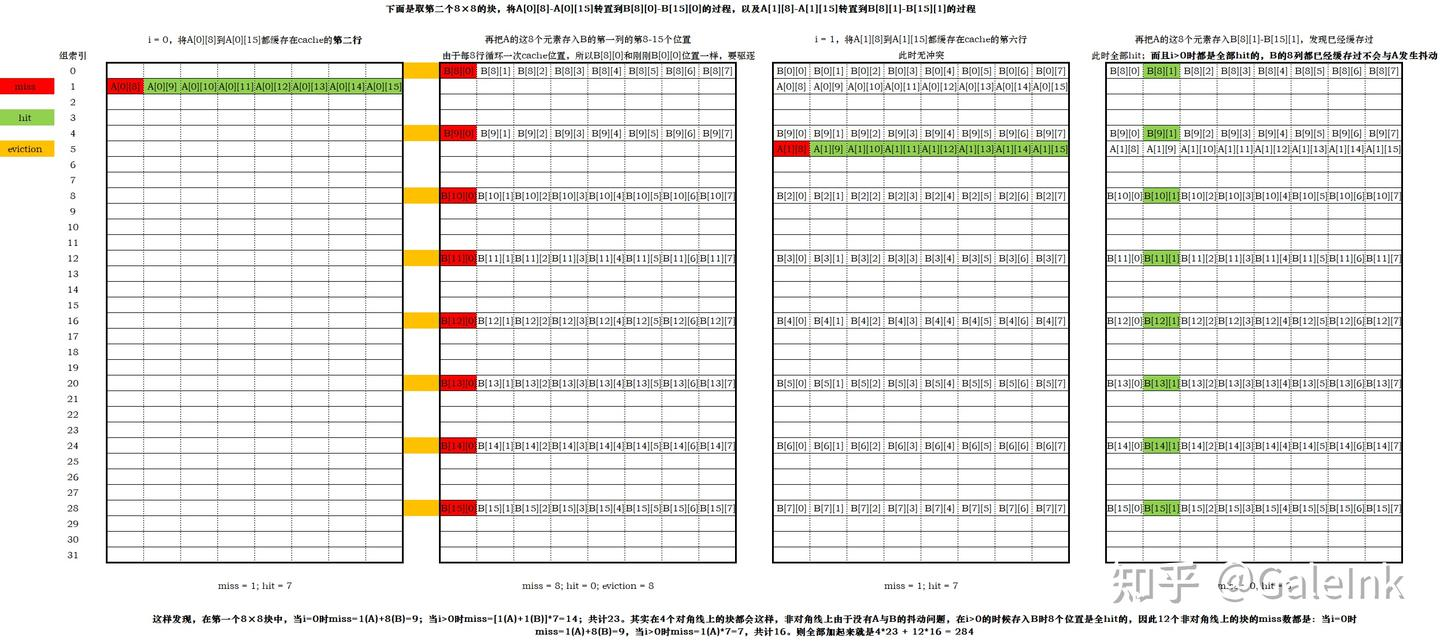
对于32×32矩阵A[32][32],每行32个int,那么根据256 / 32 = 8得知,每8行元素能够恰好占满这个cache。假设A[0][0]缓存在cache的第一个组的第0到3个字节,那么到A[7][31]为止,这前8行的元素能够恰好布满整个cache;当继续缓存下一个元素A[8][0]时,其缓存的位置将会回到cache的开头,也就会导致刚刚缓存了A[0][0]-A[0][7]的这8个元素的那一行被驱逐,并替换为新的一行A[8][0]-A[8][7]。
每8行元素循环一个cache,每1行元素占据4行的cache。
此外,由于A共有32行,每8行会循环占据cache的同一个位置;那么对于B,由于我们默认B的地址紧跟在A之后,所以可以看出B的首元素所占据cache的位置和A的首元素所占据cache的位置是一样的。也就是,A[0][0]和B[0][0]都会占据cache的第一行。
这样也可以看出采用8×8分块的好处:因为每8行之间不会造成驱逐,这8行能够各自独立地缓存到cache中,从而利用空间局部性减少miss数。下面来详细计算284的miss数是怎么来的。
我们先取出第一个8×8的块,循环如下:
int i, j, ii, jj, a0, a1, a2, a3, a4, a5, a6, a7;
if (N == 32 && M == 32) {
for (ii = 0; ii < N; ii += 8) {
for (jj = 0; jj < M; jj += 8) {
for (i = ii; i < ii + 8; i++) {
a0 = A[i][jj];
a1 = A[i][jj+1];
a2 = A[i][jj+2];
a3 = A[i][jj+3];
a4 = A[i][jj+4];
a5 = A[i][jj+5];
a6 = A[i][jj+6];
a7 = A[i][jj+7];
B[jj][i] = a0;
B[jj+1][i] = a1;
B[jj+2][i] = a2;
B[jj+3][i] = a3;
B[jj+4][i] = a4;
B[jj+5][i] = a5;
B[jj+6][i] = a6;
B[jj+7][i] = a7;
}
}
}
}我们先看当``ii = jj = 0时也就是第一个分块时的情况。i的取值范围是0到7,对i的每个取值内部,都将A[i][jj]`这连续的8个值取出来保存到寄存器中;然后取B的前8行的第一列元素。